Error of using alias in friend
The C++ standard requires that the type in the friend declaration must be a class or function, and cannot be a using alias.
1 | // Wrong code |
Only a concrete class can be a friend:
1 | class SomeClass; |
Clang compiles C++ to WebAssembly
1 | llc --version | grep wasm |
LLVM’s built-in IR interpreter
lli:
1 | lli test.ll |
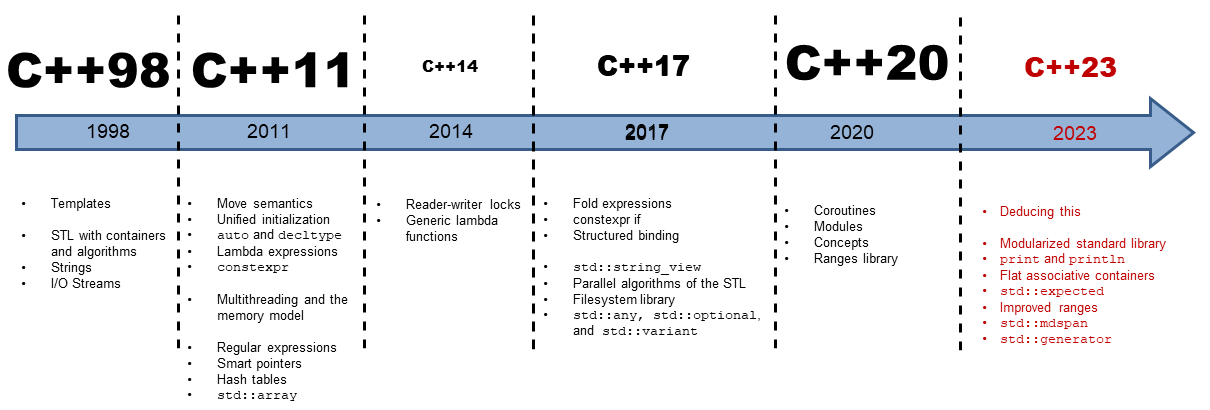
C++23: The Next C++ Standard
Standalone Build of MinGW-w64 for Windows
You can download it here, directly includes Clang: WinLibs standalone build of GCC and MinGW-w64 for Windows
[[nodiscard]]
[[nodiscard]] is an attribute introduced in C++17 that informs the compiler that a function’s return value should be used; if the return value is ignored, the compiler will issue a warning.
In functions declared with the [[nodiscard]] attribute, if the return value is not used, the compiler will emit a warning to alert developers to check their code logic. This can help developers identify potential errors and improve code maintainability.
Using the [[nodiscard]] attribute can help developers avoid common mistakes such as:
- Missing error checks
- Incorrect use of return values
- Ignoring function return values
Here is an example using the [[nodiscard]] attribute:
[[nodiscard]] int myFunction();
In this example, the myFunction() function uses the [[nodiscard]] attribute to declare that its return value should be used. If developers do not make use of the return value, the compiler will issue a warning to alert developers to check if the code is correct.
It is important to note that the [[nodiscard]] attribute is only applicable to function return values and cannot be applied to variables or other types of expressions.

C99 VAL are turing complete
Disable specific numbered warnings
1 |
|
Why can’t a constructor take an address?
C++ provides member pointer operations that can be used to get pointers to data members or member functions:
1 | struct A |
However, the C++ standard states that addresses cannot be taken for constructors. Why is that?
Is it because constructors have no return value, so they can’t use function pointer syntax? Actually, that’s not the case; the compiler generates a function for the constructor during compilation. For example, in LLVM-IR:
1 | ; Function Attrs: nounwind uwtable |
This is the same as for regular functions.
However, constructors possess some unique characteristics:
- No return value at the syntactic level
- Objects are in an incomplete state before the constructor executes
I suspect that because the object is merely a chaos of memory before execution, it needs to initialize critical information: constructing base class subobjects/polymorphic implementations, etc.
Type extraction via template specialization
In UE, the TStructOpsTypeTraits template extracts the tags of each type in this manner.
1 | template<class TYPE_NAME> |
Friendship cannot be inherited
In [ISO/IEC 14882:2014], the standard states that friendship cannot be inherited or transferred:
Friendship is neither inherited nor transitive.
1 | class A { |
Scoped enum
C++11 introduced the scoped enum:
1 | enum class EClassEnum{ |
Why was this syntax introduced? Because prior to C++11, the definitions of enum values were located within the entire enclosing namespace. The C++ standard states:
[ISO/IEC 14882:2014 §7.2]The enumeration type declared with an enum-key of only enum is an unscoped enumeration, and its enumerators are unscoped enumerators.
The following code would produce a redefinition error:
1 | enum ENormalEnum{ |
Therefore, when writing code, it is common to use a namespace to differentiate:
1 | namespace ENamespaceEnum |
Since the values of the Type enumeration are located within the current namespace, they can be used in the following manner:
1 | ENamespaceEnum::A; |
This is essentially a form of weakly-typed enumeration; the enum itself is not a type. Thus, C++11 introduced the Scoped Enum, which can be understood as a strongly-typed enumeration:
1 | enum class EScopedEnum{ |
Using it allows for the same effect as the previously used namespace form.
The values of Scoped Enumeration can also be explicitly converted to integral types:
[ISO/IEC 14882:2014 §5.2.9]A value of a scoped enumeration type (7.2) can be explicitly converted to an integral type.
Moreover, if the underlying type of the scoped enum is not explicitly specified, its default underlying type is int:
[ISO/IEC 14882:2014 §7.2]Each enumeration also has an underlying type. The underlying type can be explicitly specified using enum-base; if not explicitly specified, the underlying type of a scoped enumeration type is int.
In LLVM, the handling of Scoped enums is done in the compiler frontend. The following code generates the IR:
1 | enum ENormalEnum{ |
The LLVM-IR for the main function:
1 | ; Function Attrs: uwtable |
No symbol information is retained when generating IR, only constants remain.
LoadLibrary faild
GetLastError gets the error code:
- 126: The dependent DLL is not found.
- 127: The DLL was found, but the required symbol within the DLL is not found, usually indicating a version issue.
- 193: Invalid DLL file, please check if the DLL file is normal and if x86/x64 match.
Attention when using ## in Preprocessing
The following code compiles fine with MSVC:
1 |
|
However, it produces errors in GCC/Clang:
1 | Preprocess.cpp:16:1: error: pasting formed ',FString', an invalid preprocessing token |
This is due to GCC/Clang requiring that the result of preprocessing must consist of an already defined symbol. MSVC behaves differently in this regard, and the solution is to remove ## in places where string concatenation is not occurring:
1 |
Related issues:
- Pasting formed an invalid processing token ‘.’
- Error: Pasting formed with invalid preprocessing token
Implementation of delete[] in C++
Note: Different compiler implementations may vary; I’m using Clang 7.0.0 x86_64-w64-windows-gnu.
In C++, we can allocate memory on the heap using new and new[]. But have you considered the following question:
1 | class IntClass{ |
Since i is just a regular pointer, it has no type information. So how does delete[] know how much memory to deallocate?
Somewhere, the length information for i must definitely be stored! Let’s summon our IR code:
1 | ; Function Attrs: noinline norecurse optnone uwtable |
It can be seen that the compiler allocates 48 bytes of memory for new IntClass[10] via @_Znay(i64 48).
However, if calculated as sizeof(IntClass)*10, it should have only allocated 40 bytes of memory. The extra 8 bytes are used to store the length information of the array.
1 | %3 = call i8* @_Znay(i64 48) #8 |
It shows that the array length is written into the first 8 bytes of the allocated memory, and the real objects start getting allocated after these 8 bytes.
The address we actually get for i is the offset from the 64-bit memory storing the array length, written before the first element.
1 | // Each x represents a byte; the memory layout created by new IntClass[10] |
Since we’ve identified where it’s stored, we can modify it (prior to modification, calling delete[] i; will invoke the destructor 10 times):
1 | IntClass *i = new IntClass[10]; |
After the modification, delete[] i; will only call the destructor once, confirming our assumption.
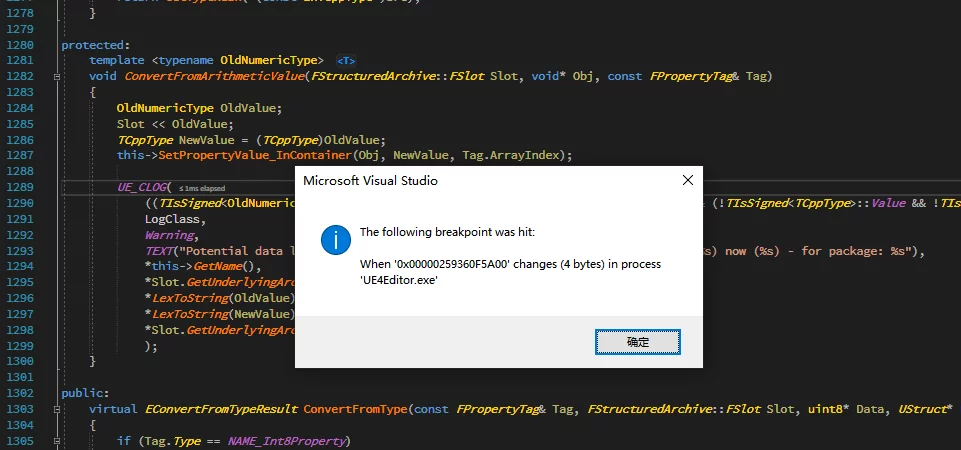
Memory Breakpoints in VS
In some debugging situations with VS, you may need to know when some objects are modified. If you debug by stepping through one point at a time, it can be inconvenient. In such cases, you can use VS’s Data Breakpoint:
The operation to add a Data Breakpoint is Debug-New BreakPoint-Data Breakpoint (or within the Breakpoint window):
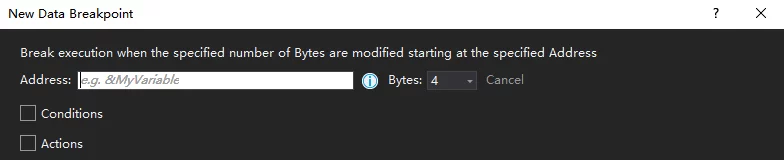
You need to enter the memory address to set the breakpoint; you can enter the address expression of the object (&Test), if you want to set a breakpoint for a non-global object, you can input the memory address directly.
To get a memory address for an object, you can add an address expression for that object under Watch (using &ival or &this->ival):
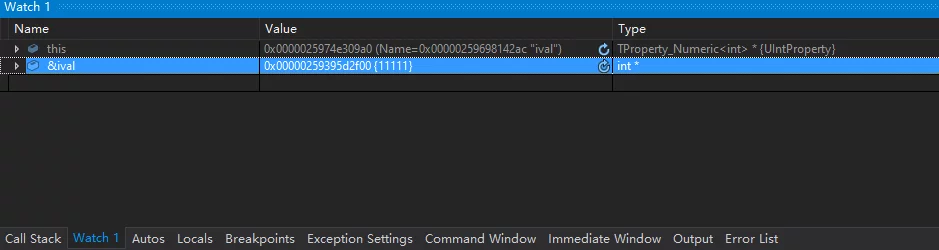
The Value will give you the memory address of the object.
Once you have the memory address, it can be filled into the Data Breakpoint in the Address section, and you specify the data size (optional 1/2/4/8):
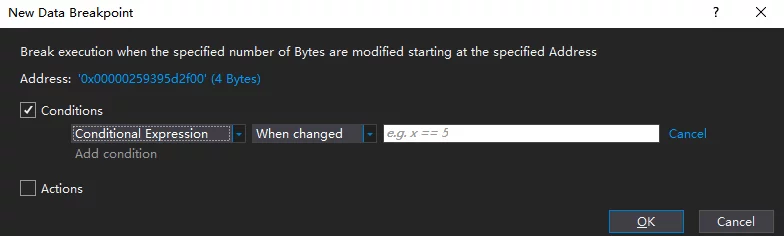
When the data at that address is modified, it will prompt that the memory breakpoint has been triggered:
Difference between move and forward
std::move and std::forward are both functions defined in <utility>.
| function | describe |
|---|---|
| x2=forward(x) | x2 is an rvalue, x cannot be an lvalue; does not throw an exception |
| x2=move(x) | x2 is an rvalue; does not throw an exception |
| x2=move_if_noexcept(x) | if x2 is movable, then x2=move(x); else x2=x; does not throw an exception |
std::move performs a simple conversion to rvalue:
1 | template<typename T> |
Indeed, move should have been named rvalue; it doesn’t actually move anything; rather, it generates an rvalue from the argument so that the object it points to can be moved.
When we use move, we inform the compiler that this object is no longer to be used in this context, allowing its value to be moved, leaving an empty object. The simplest example is the implementation of swap.
std::forward generates an rvalue from an rvalue:
1 | template<typename T> |
These two forward functions will always provide the choice between move and forward based on overload resolution. Any lvalue will be handled by the first version, while any rvalue will be handled by the second version.
1 | int i=7; |
The assertion in the second version prevents the second version from being called with a left value using explicit template arguments.
The typical use of forward is to perfectly forward an argument to another function.
When the system steals the representation of an object through move operations, use move; when you want to forward an object, use forward. Thus, forward is always safe, while move marks x for destruction, so caution should be exercised when using it. After calling std::move(x), the only valid use of x is for destruction or assignment purposes.
Overloading Rules for rvalue and lvalue
Implementing non-const lvalue version
If a class only implements:
1 | A(A&){} |
Then the class can only be called with lvalue but not with rvalue. As shown in the following code:
1 | class A{ |
The following error will occur:
1 | C:\Users\visionsmile\Desktop\cpp\rvalue.cpp:31:4: error: no matching constructor for initialization of 'A' |
Implementing const lvalue version
If a const version is implemented:
1 | A(const A& In){printf("A(const A& In);\n");} |
Then it can be called both with rvalue and with lvalue.
Only implementing rvalue version
If the class contains only rvalue function versions:
1 | A(A&& rIn){printf("A(A&& In);\n");} |
Then it can only be called with rvalue, but not with lvalue.
1 | class A{ |
This will cause the following compile error:
1 | C:\Users\visionsmile\Desktop\cpp\rvalue.cpp:31:4: error: call to implicitly-deleted copy constructor of 'A' |
Having both rvalue and lvalue versions
If both rvalue and lvalue versions are provided, it can distinguish capabilities serving rvalue and lvalue.
1 | class A{ |
Conclusion
If the class does not provide move semantics and only offers regular copy constructors and copy assignment operators, rvalue references can invoke them.
Therefore, std::move means: call move semantics; otherwise, call copy semantics.
rvalue and lvalue
rvalue (left value) refers to an expression of an object. Literally, left value means something that can be on the left side of an assignment operator. However, not all left values can be on the left side of an assignment operator; a left value may also refer to a constant.
To be supplemented.
C++ Object Destruction Order
The C++ standard stipulates that destruction occurs in reverse order of construction.
[ISO/IEC 14882:2014 § 6.6] On exit from a scope (however accomplished), objects with automatic storage duration (3.7.3) that have been constructed in that scope are destroyed in the reverse order of their construction.
Postfix & and && Modifiers of C++ Functions
Consider the following example code:
1 | template<typename T> |
What is the role of the & and && modifiers after the A::Get function?
Essentially, these two functions have different return types, but their signatures only differ in return type, and since the signatures of class member functions do not include the return type, this results in a redefinition error. The purpose of these two modifiers is to make their signatures different.
The signature of class member functions consists of:
- name
- parameter type list
- the class of which the function is a member
- cv-qualifiers (if any)
- ref-qualifier (if any)
The syntax description for the declaration part can be found in [ISO/IEC 14882:2014 § 8 Declarators].
Static Linkage Issue
In global/namespace scope, a static function/variable is available only in the translation unit (translation unit) where it is defined, and is not available in other translation units.
For instance, with three files:
1 | // file.h |
1 | // file.cpp |
1 | // main.cpp |
Using the following command to compile:
1 | # Note that there are two translation units main.cpp/file.cpp |
A linking error will occur:
1 | In file included from main.cpp:2: |
This is because func is a static function, and is defined in the translation unit of file.cpp. Due to the internal linkage nature of static objects, the translation unit of main.cpp does not contain the definition of func, hence the linking error.
Knowing the reason, there are two solutions:
- Remove
staticfromfunc; - Include the definition of
funcin all translation units wherefuncis used.
Placement-new Compilation Errors
1 | 'operator new' : function does not take 2 arguments |
This error arises because new.h or new has not been included.
The Next Big Thing: C++20
This article briefly introduces the history of C++ standards and trends for new standards.
Variable Optimized and Not Available
In VS debugging, sometimes you may find in the Debug window that the variable has been optimized and is not available, causing you to be unable to see the object’s value. Optimization can be disabled in the project’s settings in VS.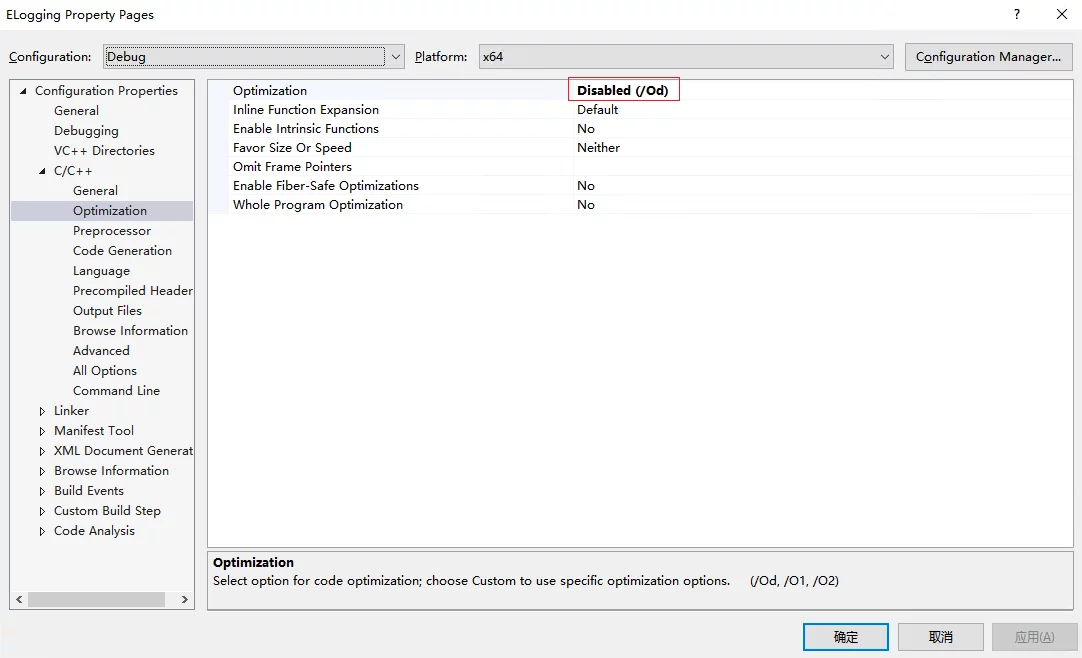
C5083 Error
1 | error C5038: data member 'UTcpNetPeer::ConnectionState' will be initialized after data member 'UTcpNetPeer::OpenedTime' |
This shouldn’t be considered an actual error; it’s merely a warning due to UE 4.22’s high warnings level. This warning signifies that the order of initialization of data members in the constructor’s definition is different from that in the declaration, so it is advisable to correct it. However, if the amount of changes required is too large, you can disable warning C5083.
1 |
Property Macros in VS
When configuring include paths or linking libraries in VS, you need to specify the paths, but absolute paths can be cumbersome. You can use property macros in VS for settings. Some common ones include:
SolutionDir: The path of the solution.ProjectDir: The path of the project.ProjectName: The name of the project.Platform: The platform (x86/x64, etc.)Configuration: The configuration (Debug/Release)RuntimeLibrary: The type of runtimeMT/MD- You can also include user-defined environment variables in the system, such as
$(BOOST).
The usage is $(VAR_NAME), for example, $(SolutionDir).
Microsoft has a page that lists available property macros in VS: Common macros for MSBuild commands and properties
In VS, you can also find the list of supported macros through Project Properties-Configuration Properties-C/C++-General-EditAdditional Include Direcories-Macro: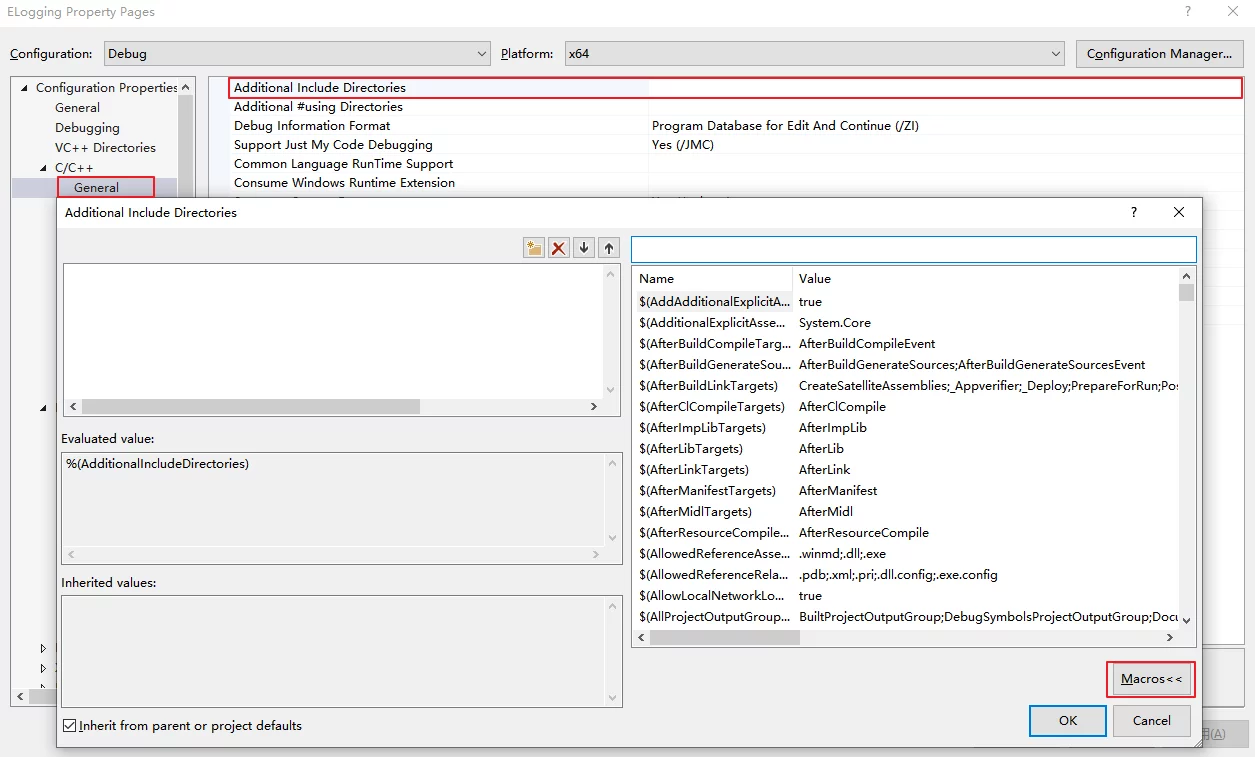
Link Error When Using Win Libraries Without Linking Library
When using MessageBoxA in the code, a linking error occurs:
1 | 1>------ Build started: Project: ELogging, Configuration: Debug x64 ------ |
It states that the symbol __imp_MessageBoxA used in WriteMsgs is not defined.
This symbol is defined in user32.lib, which needs to be added to the project; it was initially thought that all Win libraries’ libs are linked by default, but that isn’t the case.
Related issues: junk.obj : error LNK2019: unresolved external symbol __imp_MessageBoxA referenced in function main
Link Error LINK1112 When Introducing External Libraries
1 | libboost_thread-vc140-mt-gd-1_62.lib(thread.obj) : fatal error LNK1112: module machine type 'x86' conflicts with target machine type 'x64' |
This error indicates that the target machine for the project being compiled is x64, while the referenced libboost_thread-vc140-mt-gd-1_62.lib is x86, resulting in this error.
LINK2038 Link Error When Importing External Libraries
1 | 2>Generating Code... |
The key point of this error is that the current project’s compiled Runtime Library type is MTd_StaticDebug while the dependent linked library libboost_thread-vc140-mt-gd-1_62.lib is MDd_DynamicDebug, which causes a mismatch during linking:
1 | error LNK2038: mismatch detected for 'RuntimeLibrary': value 'MDd_DynamicDebug' doesn't match value 'MTd_StaticDebug' in ELogging.obj |
Knowing the issue, the solution is to make the RuntimeLibrary type of the current compiled project consistent with all dependent lib’s RuntimeLibrary types.
To modify: Project Properties-Configuration-C/C++-Code Generation-Runtime Library:

This is a pitfall; when introducing external Libs, you must clearly understand the types that the project depends on.
Precompiled C1010 Error
When compiling code, an error occurred in a .cpp file where all the code was commented out:
1 | fatal error C1010: unexpected end of file while looking for precompiled header. Did you forget to add '#include "stdafx.h"' to your source? |
This prompts that the precompiled header stdafx.h was not added to the file. Although the error can be reported by including the file, I do not need to include it here.
You can go to Project Properties-C/C++-Precompiled Header, change Precompiled Header to Not Using Precompiled Headers, and recompile. The downside is that precompiled headers cannot be used to speed up compilation.
Precompiled headers refer to the practice of compiling certain standard headers used in a project (such as Windows.h, Afxwin.h) beforehand, so that during the project’s compilation, this portion does not need to be recompiled and only the precompiled result is used. This can speed up compilation time.
The precompiled header file is generated by compiling
stdafx.cpp, named after the project. Since the suffix of the precompiled header file ispch, the compiled result file isProjectName.pch.
The compiler uses a header filestdafx.hto utilize the precompiled header file. The name of this header file can be specified in the project’s compilation settings (Project Properties-C/C++-Precompiled Header-Precompiled Header File).
The compiler assumes that all code before the directive#include "stdafx.h"is precompiled, skips the#include "stdafx.h"directive, and usesProjectName.pchto compile all code after this directive. Thus, the first statement of all CPP implementation files is#include "stdafx.h".
In-Class Default Values and Constructor Initialization Order
In C++11, in-class initialization mechanism was introduced:
1 | class A{ |
However, this introduces a question: if I use both in-class initialization and constructor initialization, what value is actually used?
1 | class A{ |
What should be the value of ival in the code above?
This is clearly answered in the C++ standard:
[IOS/IEC 14882:2014 §12.6.2.9] If a given non-static data member has both a brace-or-equal-initializer and a mem-initializer, the initialization specified by the mem-initializer is performed, and the non-static data member’s brace-or-equal-initializer is ignored.
1 | struct A { |
The A(int) constructor will simply initialize i to the value of arg, and the side effects in i’s brace-or-equal-initializer will not take place.
Nonetheless, I wish to analyze how the compiler handles this in practice. In previous articles and notes, I learned that the compiler merges the in-class initialization operation into the constructor, executing after the base class construction, but before the constructor body of itself. I continue to use LLVM-IR code analysis:
1 | class A{ |
Its constructor’s IR code is as follows:
1 | ; Function Attrs: noinline optnone uwtable |
We can see that it first initializes the this pointer, then uses it to retrieve member ival, and then initializes it (store operation in IR).
What if we use the constructor initialization syntax?
1 | class A{ |
The actual behavior is that ival is initialized to 11.
Its IR code is:
1 | ; Function Attrs: noinline optnone uwtable |
Through a diff analysis, we find that the only difference in IR code between the two versions is the initial value; all other logic is exactly the same:
Template Specialization for Variable Templates
Sum:
1 | template <int EndPoint> |
Fibonacci N-th term:
1 | template <int EndPoint> |
The maximum supported parameter depends on the compiler’s maximum recursion depth, Clang can specify this with -ftemplate-depth=N.
note: use -ftemplate-depth=N to increase recursive template instantiation depth
What is the Object in C/C++?
First, let’s talk about object in C++:
In some textbooks, the object in C++ is often portrayed as being object-oriented, where the object refers to class objects. However, the C++ standard defines object not so narrowly; in C++, anything that occupies storage space is an object (with the exception of functions).
[ISO/IEC 14882:2014 §1.8] An object is a region of storage. [ Note: A function is not an object, regardless of whether or not it occupies storage in the way that objects do. — end note ] An object is created by a definition (3.1), by a new-expression (5.3.4) or by the implementation (12.2) when needed.
Some argue that only class objects in C++ are considered objects; this is a narrow perspective. If only class objects can be called objects, how should we describe instances of built-in types? Moreover, a class itself is meant to provide the same operational capabilities as built-in types; unifying the term for entities by calling them objects is more appropriate.
[ISO/IEC 14882:2014 §1.8] An object can have a name (Clause 3). An object has a storage duration (3.7) which influences its lifetime (3.8). An object has a type (3.9). The term object type refers to the type with which the object is created.
From the perspective of object-oriented theory’s encapsulation, inheritance, and polymorphism, indeed only class objects qualify as objects in that context. However, the C++ standard’s object model is based on storage and objects (An object is a region of storage).
The concept of object in the C language is similar to that in C++, which is also defined as storage being an object:
[ISO/IEC 9899:1999 §3.14] region of data storage in the execution environment, the contents of which can represent values
Why C++ Templates Must Provide Declarations and Definitions
Because using templates in C++ generates new types, and only the translation unit currently using the template will generate these (as the compiler will only deduce templates for the current translation unit). If the declaration and definition of the template are separated and a symbol (type) is produced when using the template, the compiler will seek the definition of that symbol. The challenge arises if the template’s definition is in other translation units, because the compiler cannot reach it. How can a declaration of a symbol generated in one translation unit have the same definition in another translation unit? This is because the compiler can only know the specific location of the template when it uses the exact place to instantiate it with template arguments. The outcome is a linking error.
Thus, templates must provide both declarations and definitions to ensure consistent generation of declared and defined symbols from templates (thinking of templates as inline code enhances understanding).
Historically (C++03), C++ allowed separated compilation of templates (using export), but this feature was deprecated after C++11: primarily due to its significant limitations (not unlike normal separated declaration-definition compilation—that still requires code implementation during compilation) and because it was hard to implement (only one compiler, Comeau, has achieved this).
Changing File Encoding in VS
Choose Tools-Customize-Commands: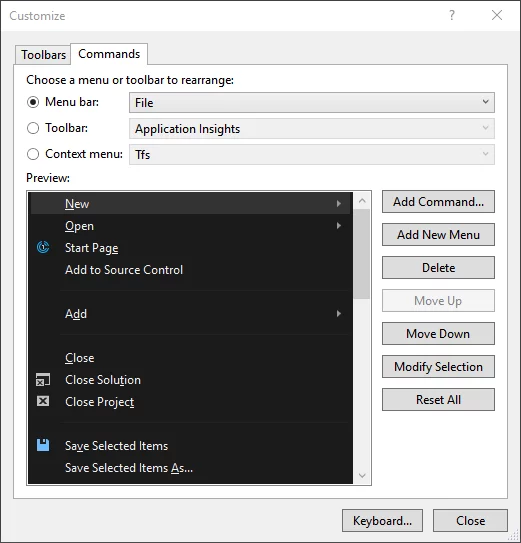
In File, add the Advanced Save Options option: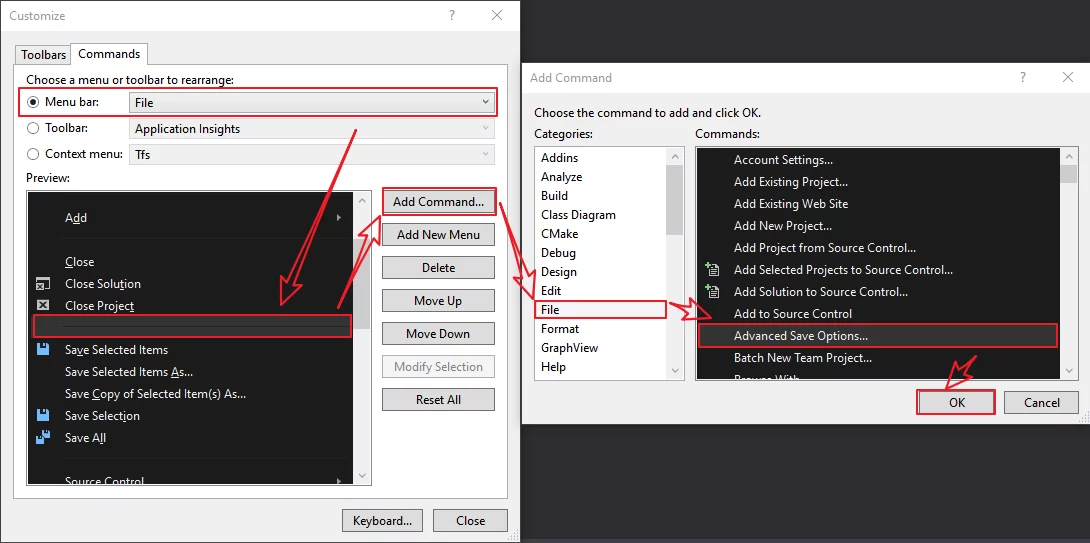
Then, opening text files will allow you to see the Advanced Save Options option under the File menu in VS: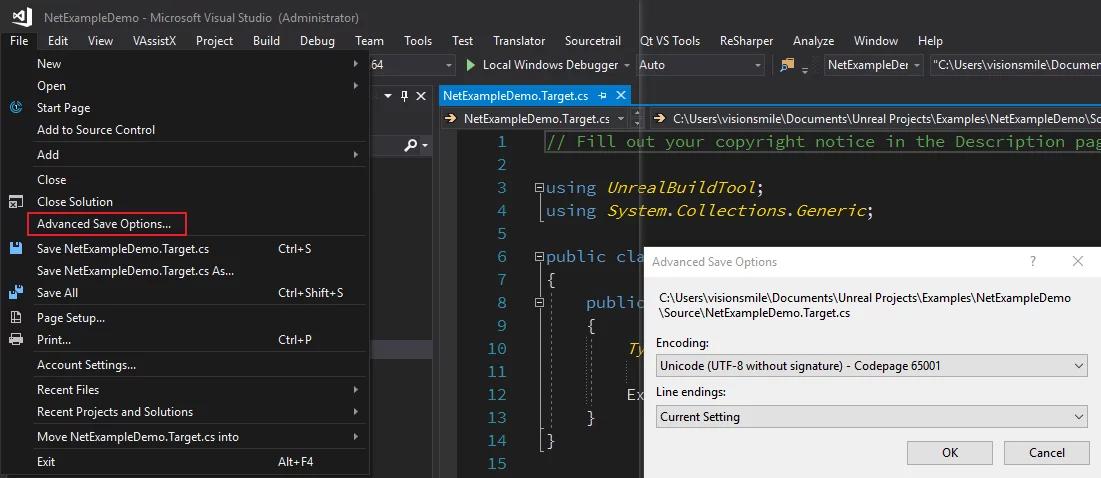
Or, install the plugin ForceUTF8(NoBOM)
PS: It is best to use Unicode encoding for code to avoid strange compilation errors caused by encoding issues.
Static Members of C++ Template Specialization Instances
Each class template specialization instance derived from a template class has its own separate static members:
1 | template <typename T> |
[ISO/IEC 14882:2014 § 14.7] Each class template specialization instantiated from a template has its own copy of any static members.
The Reason Why this Cannot Be Used as Default Parameters in Functions
Note: The implementation of member functions (passed this) is Implementation-defined.
In a previous article, I mentioned the distinction between C++ member functions and ordinary functions; member functions have an implicit this pointer:
1 | void func(){} |
Their differences are:
1 | // ::func |
Essentially, the call to a member function is passing the address of the current object as an actual argument to the function parameter this.
The reason this cannot be used in member function default parameters is that, in C++, the order of evaluation of function parameters is unspecified:
[ISO/IEC 14882:2014 §8.3.6.9] A default argument is evaluated each time the function is called with no argument for the corresponding parameter. The order of evaluation of function arguments is unspecified. Consequently, parameters of a function shall not be used in a default argument, even if they are not evaluated. Parameters of a function declared before a default argument are in scope and can hide namespace and class member names.
1 | int a; |
From the analysis above, we understand that the this pointer is essentially a function parameter. Therefore, if we were to allow this to be a default parameter for a function, it would imply:
1 | class A{ |
Such syntax would mean that one parameter’s default argument relies on another parameter, and since the order of parameter passing in functions is unspecified, this cannot be used in default arguments.
The rules of the standard are interconnected; if a rule applies here, it must also be limited in another context.
Extracting the Number of Elements in an Array
1 |
|
Bin2Hex
I wrote a small tool to convert binary files to hex data by reading the binary file byte by byte and writing it into a string:
Download bin2hex, usage is as follows:
1 | # bin2hex.exe FileName |
It will generate a file named Icon_ico.h in the current directory, recording the binary data of Icon.ico:
1 | // Icon_ico.h |
To use it, simply write the data to a file in binary mode for recovery:
1 | // hex2bin.cpp |
This method is useful for embedding resources directly into console applications during compilation.
Reading and Writing Binary Files in C
Reading:
1 | FILE* fp=fopen(rFileName, "rb"); |
Writing:
1 | static const unsigned char |
GNU Extension: struct Initialization [first … last]
GNU’s extension supports a syntax for structure initialization (Designated-Inits) like this:
1 |
|
This code means to initialize the ival member of all elements within DataList to 2.
1 |
|
Though one could also implement it using a loop:
1 |
|
However, comparing the assembly code of the two:
1 | ############################### |
1 | ############################### |
As can be seen, the direct initialization is more efficient. However, from the perspective of “readability” (after all, it is not standard C) and “portability,” writing a loop for assignment is more reliable.
Static Member Initialization Can Access Private Members
C++’s static member initialization can access the private members of a class:
1 | class process { |
[ISO/IEC 14882:2014 §9.4.2] The static data member run_chain of class process is defined in global scope; the notation process::run_chain specifies that the member run_chain is a member of class process and in the scope of class process. In the static data member definition, the initializer expression refers to the static data member running of class process. — end example ]
Usage of !!
I’ve seen the use of ! as follows:
1 | int main() |
The effect is that if ival is 0, !!ival equals 0, and if ival is non-zero, the result is 1.
Here are the IR comparisons of the two pieces of code:
1 | // cpp |
Using !! in the code:
1 | // cpp |
Enums in the C Language are Just Integers
[ISO/IEC 9899:1999 §6.4.4.4.2] An identifier declared as an enumeration constant has type int.
[ISO/IEC 9899:1999 §6.7.2.2.3] The identifiers in an enumerator list are declared as constants that have type int and may appear wherever such are permitted.
Note: Enums in C++ differ from C, with C++ enums being a distinct type, please refer to [ISO/IEC 14882:2014 C.16 Clause7].
Pure Virtual Functions in C++ Cannot Provide Definitions
[ISO/IEC 14882:2014 §10.4] A function declaration cannot provide both a pure-specifier and a definition.
1 | struct C { |
Regular Expression for Matching C Function Declarations
1 | ^([\w\*]+( )*?){2,}\(([^!@#$+%^;]+?)\)(?!\s*;) |
Source: Regex to pull out C function prototype declarations?
Aggregation Structure Initialization in C
C language supports such an initialization method for aggregate structures:
1 | struct { int a; float b; } x = { .a = 2, .b = 2.2 }; |
This is because the initializer’s designator can be either [constant-expression] or .identifier.
PS: The question of sizeof(w) == ? is an interesting one.
For details, see [ISO/IEC 9899:1999 §6.7.8].
Function Calls via Function Pointers Cannot Use Default Parameters
As the title suggests:
1 | void func(int ival=123) |
First, let’s look at when the default parameters for functions get filled in; we can analyze this via the LLVM-IR code:
1 | void func(int ival=123) |
The IR code for the main function is:
1 | define dso_local i32 @main() #6 { |
We can see that during compilation, the omitted argument is directly replaced by the default value.
Function pointers only possess the address value of the function without any information about the actual parameters, so default parameters cannot be used when accessing via function pointers.
Note: The same applies to member function pointers.
Unspecified Behavior
behavior, for a well-formed program construct and correct data, that depends on the implementation. [ Note: The implementation is not required to document which behavior occurs. The range of possible behaviors is usually delineated by this International Standard. — end note ]
Well-formed Program
[ISO/IEC 14882:2014 §1.3.26] C++ program constructed according to the syntax rules, diagnosable semantic rules, and the One Definition Rule (3.2).
Implementation-Defined Behavior
[ISO/IEC 14882:2014] behavior, for a well-formed program construct and correct data, that depends on the implementation and that each implementation documents.
Undefined Behavior (UB)
[ISO/IEC 14882:2014 §1.9.4] This International Standard imposes no requirements on the behavior of programs that contain undefined behavior.
[ISO/IEC 14882:2014 §1.3.24] behavior for which this International Standard imposes no requirements [ Note: Undefined behavior may be expected when this International Standard omits any explicit definition of behavior or when a program uses an erroneous construct or erroneous data. Permissible undefined behavior ranges from ignoring the situation completely with unpredictable results, to behaving during translation or program execution in a documented manner characteristic of the environment (with or without the issuance of a diagnostic message), to terminating a translation or execution (with the issuance of a diagnostic message). Many erroneous program constructs do not engender undefined behavior; they are required to be diagnosed. — end note ]
This means programs with UB exhibit unpredictable behavior, and any circumstances may occur.
About the Injected Class Name Issue
First, let’s understand what injected-class-name means:
[ISO/IEC 14882:2014(E) §9.0.2] The class-name is also inserted into the scope of the class itself; this is known as the injected-class-name. For purposes of access checking, the injected-class-name is treated as if it were a public member name.
This means that the name of the class is embedded in the scope of the class; for the purpose of access checking, the injected class name is treated as a public member (note this sentence).
The declaration of the injected class name is similar to the following:
1 | class A { |
Name lookup within a class starts from the current scope, and the injected class name is more evident in the inheritance hierarchy:
1 | class A{}; |
As shown in the above code, B::A can be used to qualify the type A in the inheritance hierarchy of B.
In the description above, it states that the injected class name is treated as a public member; what happens if we mark the base class as private in the inheritance hierarchy?
1 | class A { }; |
Let’s compile this code:
1 | injected-class-name.cpp:4:3: error: 'A' is a private member of 'A' |
What about using B::A or C::A? The same error will occur.
Because name lookup for the base class name in the derived class finds the injected class name:
[ISO/IEC 14882:2014(E) §11.1.5] In a derived class, the lookup of a base class name will find the injected-class-name instead of the name of the base class in the scope in which it was declared.
To resolve such issues, you should qualify the namespace (in the example above, change it to ::A):
1 | class A { }; |
Note that within the scope of the namespace, the default name lookup is namespace qualified.
A C++ Issue that Trims Words
Question: Can a derived class’s object access its base class members?
A) Public members of public inheritance
B) Private members of public inheritance
C) Protected members of public inheritance
D) Public members of private inheritance
At first glance, it seems that derived classes under inheritance using public/protected/private can access base class public/private members, so options A, C, and D seem valid.
However, note that the question refers to objects; objects can only access public members of the class, hence I have bolded that point in the question. :)
Pointer to Integral Conversion using reinterpret_cast
Pointer to Integer Conversion
A pointer can be explicitly converted to any integral type that can hold it, but the mapping function is implementation-defined.
The value of type std::nullptr_t can be converted to an integral type, and this conversion is equivalent to converting (void*)0 to an integral type.
Note: reinterpret_cast cannot be used to convert any type of value to std::nullptr_t.
[ISO/IEC 14882:2014 §5.2.10.4] A pointer can be explicitly converted to any integral type large enough to hold it. The mapping function is implementation-defined. [ Note: It is intended to be unsurprising to those who know the addressing structure of the underlying machine. — end note ] A value of type std::nullptr_t can be converted to an integral type; the conversion has the same meaning and validity as a conversion of (void*)0 to the integral type. [ Note: A reinterpret_cast cannot be used to convert a value of any type to the type std::nullptr_t. — end note ]
Integral to Pointer Conversion
Integral or enumeration types can be explicitly converted to pointers. A pointer converted to a sufficiently large integral type (if such exists in the implementation) and back to the same pointer type will retain its original value.
This means that this conversion does not result in undefined behavior (the mapping between pointers and integers otherwise remains implementation-defined):
1 | // Compile using c++ compiler |
[ISO/IEC 14882:2014 §5.2.10.5] A value of integral type or enumeration type can be explicitly converted to a pointer. A pointer converted to an integer of sufficient size (if any such exists on the implementation) and back to the same pointer type will have its original value; mappings between pointers and integers are otherwise implementation-defined. [ Note: Except as described in 3.7.4.3, the result of such a conversion will not be a safely-derived pointer value. — end note ]
Function Pointer Conversion
Function pointers can be explicitly converted to function pointers of different types; calling a function through a converted function pointer may have effects differing from the function defined.
1 | void func(int ival) |
Unless converting a type pointer to T1 to pointer to T2 (where T1 and T2 are function types) and converting back to its original type yields the original pointer value, such pointer conversions result in unspecified behavior.
[ISO/IEC 14882:2014 §5.2.10.6] A function pointer can be explicitly converted to a function pointer of a different type. The effect of calling a function through a pointer to a function type (8.3.5) that is not the same as the type used in the definition of the function is undefined. Except that converting a prvalue of type “pointer to T1” to the type “pointer to T2” (where T1 and T2 are function types) and back to its original type yields the original pointer value, the result of such a pointer conversion is unspecified. [ Note: see also 4.10 for more details of pointer conversions. — end note ]
offsetof Cannot Be Used on Non-POD Types (Standard Layout)
offsetof is a macro defined in stddef.h/cstddef which is used to obtain the offset of a structure member in that structure.
1 | class A{ |
However, it cannot be used on types that are not Standard Layout Classes, as this results in undefined behavior:
[ISO/IEC 14882:2014 §18.2.4]: The macro offsetof(type, member-designator) accepts a restricted set of type arguments in this International Standard. If type is not a standard-layout class (Clause 9), the results are undefined. The expression offsetof(type, member-designator) is never type-dependent (14.6.2.2) and it is value-dependent (14.6.2.3) if and only if type is dependent. The result of applying the offsetof macro to a field that is a static data member or a function member is undefined. No operation invoked by the offsetof macro shall throw an exception and noexcept(offsetof(type, member-designator)) shall be true.
Note that offsetof is required to work as specified even if the unary operator& is overloaded for any of the types involved.
Let’s also review what Standard Layout types are:
[ISO/IEC 14882:2014 §3.9.9]: Scalar types, standard-layout class types (Clause 9), arrays of such types and cv-qualified versions of these types (3.9.3) are collectively called standard-layout types.
And Standard Layout Class is defined as:
A standard-layout class is a class that:
- has no non-static data members of type non-standard-layout class (or an array of such types) or reference,
- has no virtual functions (10.3) and no virtual base classes (10.1),
- has the same access control (Clause 11) for all non-static data members,
- has no non-standard-layout base classes,
- either has no non-static data members in the most derived class and at most one base class with non-static data members, or has no base classes with non-static data members, and
- has no base classes of the same type as the first non-static data member.
That is, if a class contains any of these, it is a non-standard layout class, and offsetof cannot be used on it.
Standard Layout Types in C++
Let’s also review what Standard Layout types are:
[ISO/IEC 14882:2014 §3.9.9]: Scalar types, standard-layout class types (Clause 9), arrays of such types and cv-qualified versions of these types (3.9.3) are collectively called standard-layout types.
And Standard Layout Class is defined as:
A standard-layout class is a class that:
- has no non-static data members of type non-standard-layout class (or an array of such types) or reference,
- has no virtual functions (10.3) and no virtual base classes (10.1),
- has the same access control (Clause 11) for all non-static data members,
- has no non-standard-layout base classes,
- either has no non-static data members in the most derived class and at most one base class with non-static data members, or has no base classes with non-static data members, and
- has no base classes of the same type as the first non-static data member.
Placing “new” on the “this” Pointer of a Base Class Subobject
Doing this results in UB; let’s look directly at the code in the standard ([ISO/IEC 14882:2014 §3.8.5]):
1 |
|
The lifetime of this ends after the destructor is called; calling the destructor means all data within that class becomes meaningless, and operating on meaningless data results in UB.
Compiling 32-bit Programs with MinGW-W64
GCC supports the -m32 option to compile code to 32-bit programs. However, if your MinGW uses the SEH or DWARF exception model, these are single-platform and do not support 32-bit compilation.
There is an answer on stackoverflow: How do I compile and link a 32-bit Windows executable using mingw-w64
There is also a question on CSDN: How to compile a 32-bit program with MinGW-w64
Solution: You can choose the SJLJ exception model version for download from here, or use TDM GCC (which has only been updated to MinGW5.1.0).
Implicit Function Declarations in C
The following code:
1 | // hw.c |
Compiling with gcc will succeed and execute (with a warning):
1 | $ gcc hw.c -o hw.exe |
This raises the question: why does my current compilation unit compile successfully without including printf‘s declaration?
Because the history of C language supported implicit function declaration (C89 supports implicit declarations):
[ISO/IEC 9899:1990 6.3.2.2] If the expression that precedes the parenthesized argument list in a function call consists solely of an identifier and if no declaration is visible for this identifier, the identifier is implicitly declared exactly as if, in the innermost block containing the function call, the declaration
1 | extern int identifier(); |
However, this feature was removed in C99:
[ISO/IEC 9899:1999 Foreword] remove implicit function declaration
The above code is equivalent to:
- The compiler implicitly declares the
printffunction. - The linker defaults to linking
stdlib, so there is no undefined symbol linking error.
In GCC, if you don’t want the default linking, you can use linker parameters (here are just three of them):
- -nodefaultlibs: Does not use standard system libraries; only libraries specified in the compilation parameters will be passed to the linker.
- -nostdlib: Do not use the standard system startup files or libraries when linking.
- -nolibc: Do not use the C library or system libraries tightly coupled with it when linking.
More GCC linking parameters can be found here: 3.14 Options for Linking
Viewing Object Memory Layout with Clang
Clang can use the -cc1 -fdump-record-layouts parameters during compilation to view the memory layout of an object.
However, using the above command will not search for standard header files from the Path; we need to preprocess the source file first:
1 | $ clang++ -E main.c -o main_pp.cpp |
Then compile the preprocessed .cpp file with the -cc1 -fdump-record-layouts parameter:
1 | $ clang++ -cc1 -fdump-record-layouts main_pp.cpp |
Example:
1 | // class_layout.cpp |
Preprocess:
1 | $ clang++ -E class_layout.cpp -o class_layout_pp.cpp |
View the memory layout of the three classes:
1 | $ clang++ -cc1 -fdump-record-layouts class_layout_pp.cpp |
Refer to the article: Dumping a C++ object’s memory layout with Clang
Default Parameters of Virtual Functions Are Determined by the Caller’s (Pointer or Reference) Static Type
Previously, I wrote about this in C/C++ Standards Excerpts #override functions do not override their original default parameters, but not in enough detail, so I’ll elaborate here.
Consider the following code:
1 | class A{ |
The C++ standard stipulates the description concerning the use of default parameters for virtual functions:
[ISO/IEC 14882:2014] A virtual function call (10.3) uses the default arguments in the declaration of the virtual function determined by the static type of the pointer or reference denoting the object.
That is, the use of default parameters for a virtual function is determined by the static type of the pointer or reference denoting the object executing that virtual function call.
From the above example:
1 | int main() |
Thus, the default parameters of polymorphic functions are not dynamically bound; they are determined at compile time based on the type of the object and which default parameter to use.
Let’s take a look at the LLVM-IR code of the above:
1 | define i32 @main() #4 { |
C++ Lambda Captures
In a previous article (How Lambda is Implemented in Compilers), I mentioned that the result of a Lambda is essentially a class that overloads ().
However, regarding the capture aspect, it needs to be noted: how is the number of captures determined? If using value capture [=] or reference capture [&], will all previous data be treated as members of that Lambda?
With this question in mind, let’s explore this.
First, let’s state the conclusion: using default captures [&]/[=] does not capture all the objects above into the Lambda. Instead, only objects actually used within the Lambda expression are captured.
Look at the following example:
1 | public: |
First, let’s look at the members of this closure object (LLVM-IR):
1 | // class A |
Since it’s a value capture, the members of this closure object all make a copy.
Initially, I assumed that the generated closure object should have a constructor initializing with the captured parameters, but I’m not sure if it’s because LLVM optimizes or something else, no constructor was evidently produced. The initialization part of the captures is as follows:
1 | define i32 @main() #4 { |
Functions Types Typedef Cannot Be Used in Definitions
Consider the following situation:
1 | typedef void Func(int); |
[ISO/IEC 14882:2014 §8.3.5.10] A typedef of function type may be used to declare a function but shall not be used to define a function (8.4).
Lambda-Expressions Syntax
First, let’s look at the syntax description of Lambda-Expressions in the C++ standard (note that it is recursively described):
What does the following code express?
1 | int main() |
First, look at the first line:
1 | [](){}; |
This line declares an unnamed closure object using a lambda expression, without captures, parameters, or any implementation.
The second line:
1 | []{}(); |
This is interesting; according to the above Lambda-Expression Syntax diagram, the ${lambda\textrm{-}declarator}\_{opt}$ is Opt, indicating it may be omitted.
The ${lambda\textrm{-}declarator}$ includes `${(parameter\textrm{-}declaration\textrm{-}clause) mutable}_{opt}$, suggesting the parameter list can be omitted at the lambda expression declaration.
That means:
1 | auto lambdaObj=[](){}; |
Thus, we can interpret the first half of the second line as declaring a closure object, while the final (); calls this closure object.
The third line:
1 | {}[]{}; |
This line can also be written as:
1 | { |
A block followed by a lambda expression that creates an unnamed closure object.
A Pitfall in C++ Declaration Semantics
What is wrong with the following code? What will it output?
1 | class T |
The answer is it will output nothing!
The actual execution semantics is not as we might expect; it creates a temporary std::string variable and then executes the destructor of that temporary variable.
This is because of C++’s declaration semantics rule:
Note that the above diagram is recursively defined.
1 | std::string(hw); |
So, in the print function, a local std::string variable hw is created that hides the class-scope hw.
The solution: replace () with {}; in the previous case, using the initializer list will call the copy constructor and immediately destroy the temporary object.
In the current example, the problem is not severe. However, if this kind of operation is done on locks in multithreading, it could be highly problematic.
Why VC Outputs “烫烫烫” for Out-of-Bounds Access
When I learned C language years ago with VC, I encountered the output “烫烫烫” and similar “garbled” text when memory access went out of bounds.
For example, the following code (compiled with vs2017-debug-x86):
1 | int main() |
Using x32dbg debugger: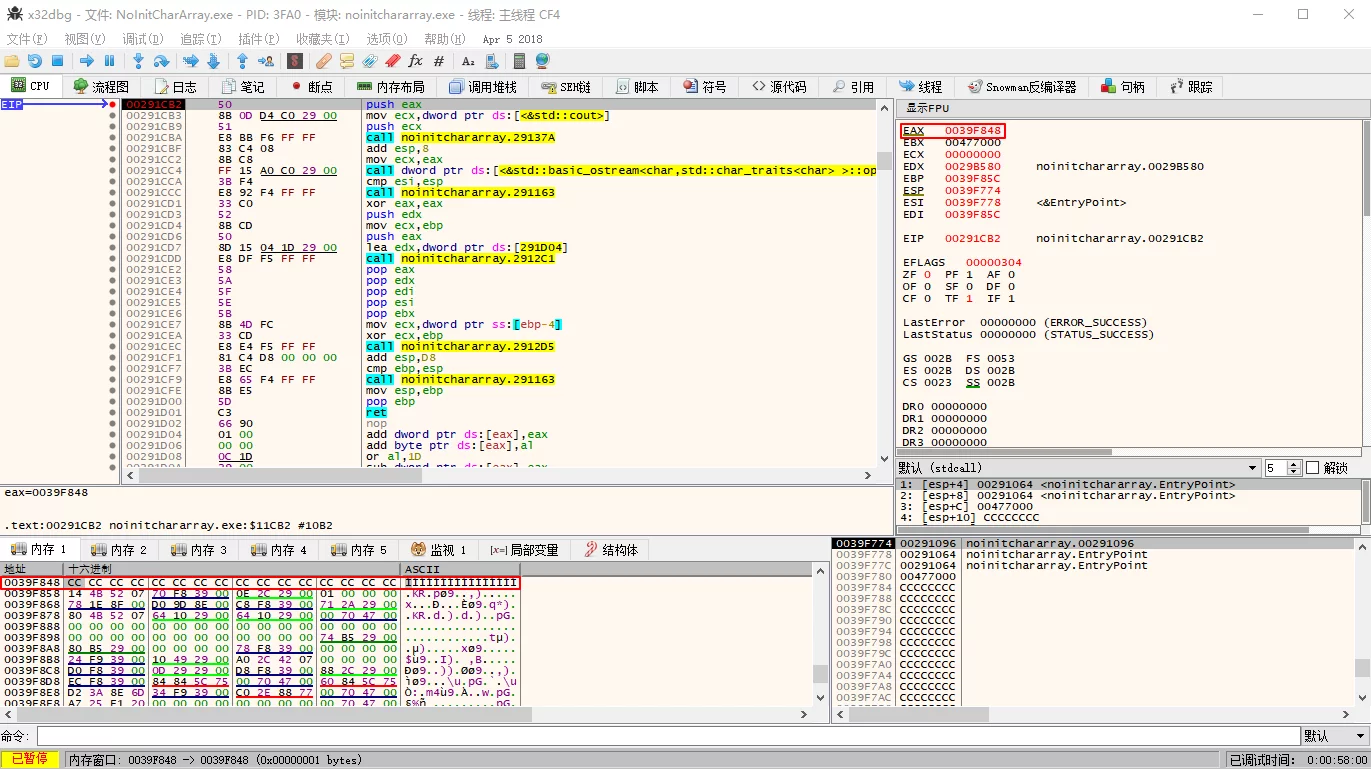
Through IDA debugger: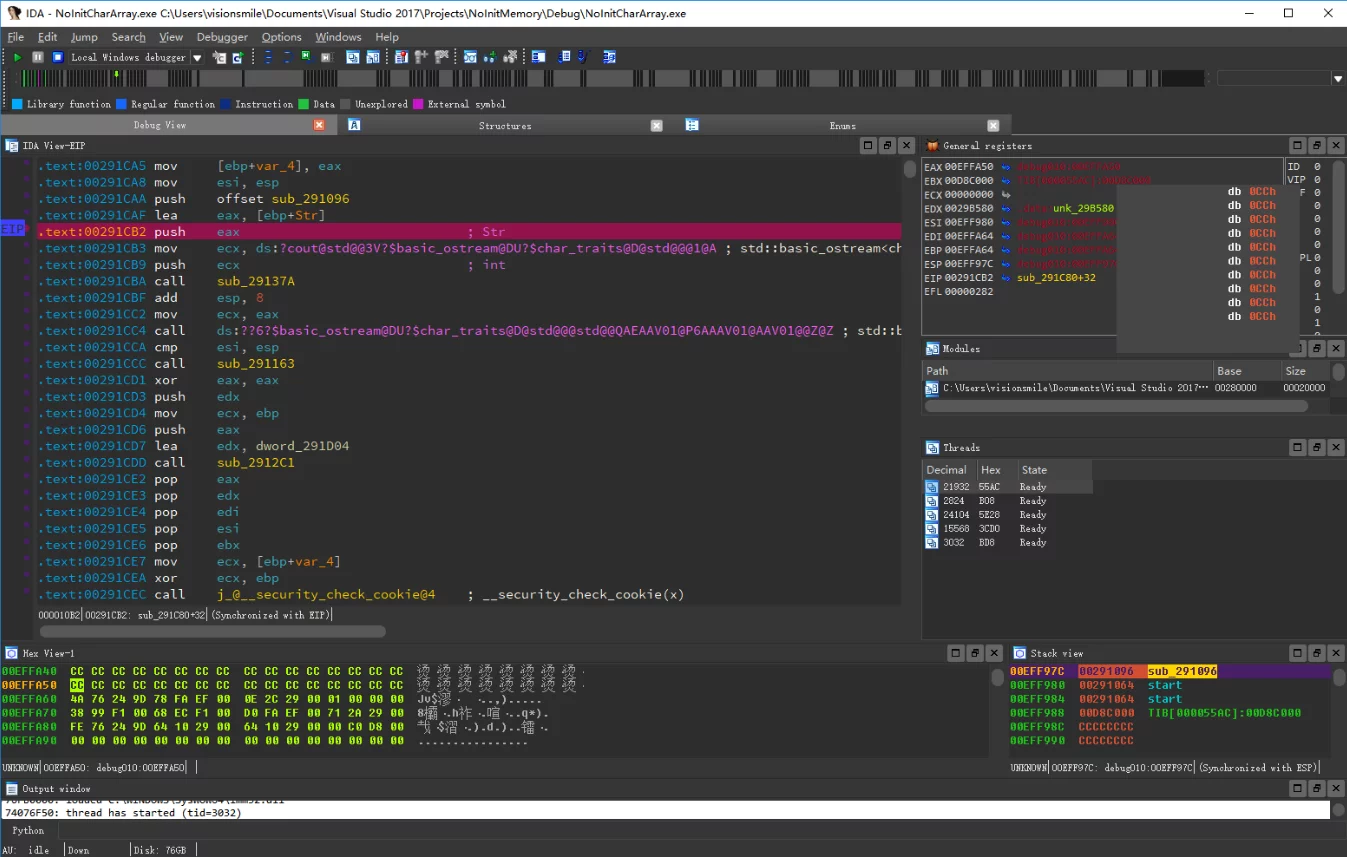
Output result: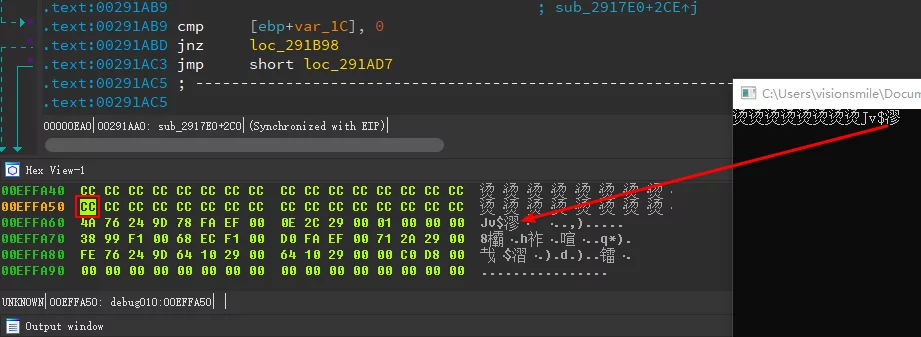
This occurs because in the debug mode, VC sets uninitialized memory to 0xCC, which in GBK encoding represents 烫.
A Bug in Clang
1 | class A{ |
The above code compiles and runs in Clang with the output bbb (the same behavior is present in the latest Clang5.0). In contrast, GCC generates a redefinition error.
I’ve dug a hole here and will analyze this problem later.
Differences Between ISO C and POSIX Definitions of Byte
ISO C
byte
addressable unit of data storage large enough to hold any member of the basic character set of the execution environment
NOTE 1 It is possible to express the address of each individual byte of an object uniquely.
NOTE 2 A byte is composed of a contiguous sequence of bits, the number of which is implementation-defined. The least significant bit is called the low-order bit; the most significant bit is called the high-order bit.
POSIX
Byte
An individually addressable unit of data storage that is exactly an octet, used to store a character or a portion of a character; see also Section 3.87 (on page 47). A byte is composed of a contiguous sequence of 8 bits. The least significant bit is called the ‘low-order’ bit; the most significant is called the ‘high-order’ bit.
Note: The definition of byte from the ISO C standard is broader than the above and might accommodate hardware architectures with different-sized addressable units than octets.
Size of Reference Member of Class
1 | struct ATest{ |
The layout of class ATest in LLVM/Clang compiles into memory layout as:
1 | %struct.ATest = type { i32* } |
As for why references are treated as pointers, please see the implementation of references.
Thus, sizeof(ATest) will produce a result of 8 in this implementation.
What is Translation Unit in C/C++?
[ISO/IEC 14882:2014]A source file together with all the headers (17.6.1.2) and source files included (16.2) via the preprocessing directive
#include, less any source lines skipped by any of the conditional inclusion (16.1) preprocessing directives, is called a translation unit. [ Note: A C ++ program need not all be translated at the same time. — end note ]
[ISO/IEC 9899:1999]
A source file together with all the headers and source files included via the preprocessing directive#includeis known as a preprocessing translation unit. After preprocessing, a preprocessing translation unit is called a translation unit.
Variable Access Across Scope in C
If you have the following C code and compile it using a C compiler.
1 | int i=123; |
Because the concept of namespace does not exist in C, you cannot use :: as in C++. However, you can use the following trick to achieve this:
1 | int i=123; |
Google C++ Style Guide
Simplified image version: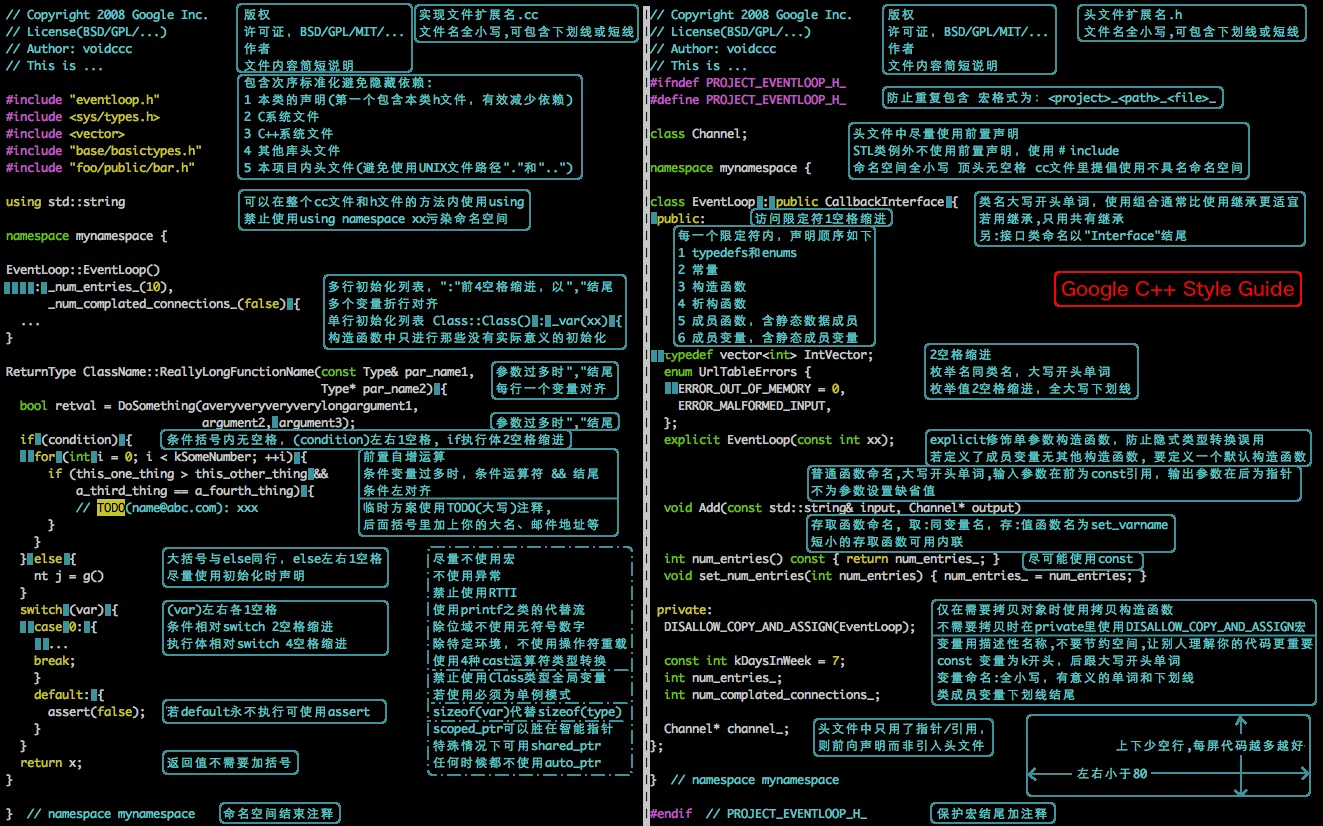
Chinese PDF version:
C++17 Feature Cheat Sheet
Value Category Cheat Sheet
New Features and Compatibility of C++11
new, Constructors, and Exceptions
The new operation actually consists of two parts:
- First, it calls operator new to allocate memory.
- Calls the constructor of the object.
Evaluation of a new expression invokes one or more allocation and constructor functions; see 5.3.4
This is important because, although there are generally no issues, it becomes crucial when considering exception safety: How to determine if an exception was thrown by operator new or the class constructor when newing an object?
If operator new throws an exception, no memory is allocated (throwing std::bad_alloc), and thus operator delete should not be called. However, if an exception is thrown in the class constructor, it means memory has been allocated, so we need to call operator delete for cleanup.
Meaning of Pointer Comparison
In C++, an object can have multiple valid addresses; therefore, pointer comparison is not about addresses but about object identity.
Common Terminology Errors in C++
A common issue is that different languages use different terminologies to describe the same behavior. For example, Java or other languages use method to describe functions within a class, while C++ does not have the concept of method; it should be called member function.
Here are some commonly misused terms in C++:
| Wrong | Right |
|---|---|
| Pure virtual base class | Abstract class |
| Method | Member function |
| Virtual method | ??? |
| Destructed | Destroyed |
| Cast operator | Conversion operator |
Why Have References?
I believe there are two fundamental reasons for references in C++:
- To prevent the overhead of object copying (more concise than pointer indirection).
- For IO stream usage (for instance, cout<<x<<y returns a reference to the stream, equivalent to using cout<<x, cout<<y).
Reasons for Certain Language Features in C++
- Namespaces provide a mechanism to deal with the same names in different libraries.
- Exception handling establishes a basis for a common model for error handling.
- Templates provide a mechanism for defining container classes and algorithms independent of specific types, where specific types can be provided by the user or other libraries.
- Constructors and destructors provide a common model for object initialization and final cleanup.
- Abstract classes provide a mechanism to define interfaces independently, regardless of the actual classes that implement them.
- Runtime type information is a mechanism to retrieve type information because when an object is passed to a library and returned, it may only carry insufficiently specific (base class) type information.