Some examples in C++ that can be confusing or have peculiar usages are recorded.
Explicitly Qualified Number of Elements for Array Arguments
When an array is passed as a function parameter, it decays to a pointer:
A declaration of a parameter as “array of type” shall be adjusted to “qualified pointer to type”.
And as mentioned earlier:
int x[3][5];Here x is a 3 × 5 array of integers. When x appears in an expression, it is converted to a pointer to (the first of three) five-membered arrays of integers.
This means that when passing an array as a parameter, the bounds will be lost (C/C++ native arrays don’t have boundary checks either…).
1 | void funcA(int x[10]){} |
The corresponding intermediate code is:
1 | ; Function Attrs: nounwind uwtable |
If the precise value of the array bounds is very important, and you want the function to only accept arrays containing a specific number of elements, you can use reference parameters:
1 | void funcC(int (&x)[10]){} |
The intermediate code is:
1 | ; Function Attrs: nounwind uwtable |
If we use an array with a number of elements not equal to 10 to pass to funcC, it will result in a compilation error:
1 | // note: candidate function not viable: no known conversion from 'int [11]' to 'int (&)[10]' for 1st argument. |
You can also use function template parameters to specify the size of the array parameters the function accepts:
1 | template<int arrSize> |
Usage:
1 | int x[12]; |
Enabling Compiler Warnings for Implicit Type Conversions Changing Sign
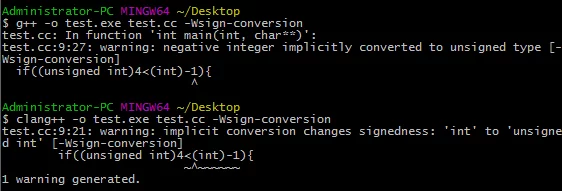
1 | if((unsigned int)4<(unsigned int)(int)-1){ |
The expression in the if statement is true (outputs yes), and no warning will be issued at compile time.
Even though we specified (int)-1, there will be an implicit conversion when comparing unsigned int and int. That is:
The usual arithmetic conversions are performed on operands of arithmetic or enumeration type.
1 | ((unsigned int)4<(unsigned)(int)-1)==true |
Warnings about conversions between signed and unsigned integers are disabled by default in C++ unless -Wsign-conversion is explicitly enabled.
By enabling -Wsign-conversion, the warning can be seen (it is recommended to enable it).
The effect of this option is:
Warn for implicit conversions that may change the sign of an integer value, like assigning a signed integer expression to an unsigned integer variable. An explicit cast silences the warning. In C, this option is enabled also by -Wconversion.
For more GCC warning options, you can check here Warning-Options
Assert
assert Defined in header
If NDEBUG is defined as a macro name at the point in the source code where <assert.h> is included, then assert does nothing.
If NDEBUG is not defined, then assert checks if its argument (which must have scalar type) compares equal to zero.
1 |
cppreference - assert
assert is only effective in debug mode; using it in release mode does nothing.
Because in VC++, release will globally define NDEBUG
The following code will compile and input a number >100 in VS with different results in debug and release mode (release will not).
1 |
|
Invalid References
Typically, the references we create are valid, but they can also be rendered invalid due to human factors…
1 | char* ident(char *p) { return p; } |
This leads to undefined behavior.
In particular, a null reference cannot exist in a well-defined program, because the only way to create such a reference would be to bind it to the “object” obtained by indirection through a null pointer, which causes undefined behavior.
References to Arrays
1 | void f(int(&r)[4]){ |
For reference types of array parameters, the number of elements is also part of its type. Typically, references to arrays are only used in templates, where references can be inferred from the array.
1 | template<class T,int N> |
The consequence is that the more different types of arrays used to call f(), the more corresponding functions are defined.
Ignoring Top-Level cv-qualifier of Function Parameters
For compatibility with C, C++ automatically ignores the top-level cv-qualifier of the parameter type.
For example, the following function would report a redefinition error in C++, rather than an overload:
1 | // Type is int(int) |
In either case, whether allowing or not allowing modification of the actual parameter, it is merely a copy of the actual argument provided by the function caller. Therefore, the calling process will not violate the data safety of the calling context.
The signature rule for functions is as follows:
<function>name, parameter type list (8.3.5), and enclosing namespace (if any)
And the function’s parameter-type-list will remove the top-level cv-qualifier:
[ISO/IEC 14882:2014 §8.3.5.5]After producing the list of parameter types, any top-level cv-qualifiers modifying a parameter type are deleted when forming the function type. The resulting list of transformed parameter types and the presence or absence of the ellipsis or a function parameter pack is the function’s
parameter-type-list.
Be Careful with signed/unsigned when using char as an array index
When the char type is used as an array index, it should first be converted to unsigned char (since char is usually signed (implementation-defined)). It cannot be directly converted to int or unsigned int, or it will lead to array index out of bounds.
1 |
|
struct tag (*[5])(float)
The type designated as ‘struct tag (*[5])(float)’ has type ‘array of pointer to function returning struct tag’. The array has length five and the function has a single parameter of type float. Its type category is array.
new a pointer array
1 | int TEN=10; |
Low-Level const and Top-Level const
Low-Level const: Indicates that the object pointed to by the pointer is a constant.
Top-Level const: Indicates that the pointer itself is constant. Top-Level const can indicate that any object is constant, which applies to any data type.
1 | int ival=0; |
Actually, I have a simple method to distinguish: look at what is modified by const on the right.
- For
int const *x=std::nullput;, const modifies*x, as x is a pointer, we temporarily regard*xas dereference, which represents the object pointed to by x, so it islow-level const. - Conversely,
int * const x=std::nullptr;, as const modifies the pointer x, so it istop-level const.
Dangers of Passing this Pointer in Constructor
If we pass the this pointer to other functions within a constructor, we could run into such problems:
1 | struct C; |
The code above seems fine, but when we construct a const C, it could lead to the following issue:
1 | const C cobj; |
The above code will compile successfully and can modify the constant object’s member i in no_opt.
Passing the this pointer of a constant object to other functions during construction means we could modify the values of the objects in that constant, which is not standard-compliant.
During the construction of a const object, if the value of the object or any of its subobjects is accessed through a glvalue that is not obtained, directly or indirectly, from the constructor’s this pointer, the value of the object or subobject thus obtained is unspecified.
Therefore, it’s best not to write anything that passes the this pointer outside the class in the constructor (it’s better to just initialize data members)…
Get the Absolute Path of the Current Executing Program
There are two methods:
1 |
|
This method has a drawback: if the executable program is added to the system PATH, it will obtain the path of the directory where it is executed.
Another method is through the Windows API:
1 | const string getTheProgramAbsPath(void){ |
In this way, irrespective of whether the program has been added to the system’s PATH or where it is executed, it will get the absolute path where this executable program is stored in the system.
A Quirky Usage of using
1 | using foofunc=void(int); |
In the code above:
1 | foofunc foo; |
is declaring a function foo; looking at the symbol information in the target file (omitting unrelated details):
1 | $ clang++ -c testusing.cc -o testusing.o -std=c++11 |
Through the c++filt toolchain in gcc, the symbols in the object file can be restored:
1 | $ c++filt _Z3fooi |
However, it is not defined, and directly linking will produce an undefined error.
Rvalue References
1 | int x=123; |
The IR code is:
1 | # Using value 123 to initialize x |
This realizes a non-copy behavior, which behaves similarly to assigning an object’s address to a pointer.
In fact, the purpose of rvalue references is to give temporary objects a longer lifespan—binding a reference to a temporary object without incurring any additional copy operations.
The same effect can be achieved with const T&:
1 | int x=123; |
And the above example will generate identical IR code under LLVM.
An Array Name Example
1 | int a[]={1,2,3,4,5}; |
How Many Passing Methods Are There?
Most people think there are the following three passing methods in C++ functions:
- Pass by value: the value of the parameter is a copy of the actual parameter;
- Pass by reference: the parameter is an alias for the actual parameter;
- Pass by pointer: passing a pointer to the object to the parameter;
In fact, in C++, there are only two passing methods: pass by value, pass by reference.
Because passing by pointer is also a type of pass by value, the parameter value is merely a copy of the actual argument; they are just both pointers.
In the father of C++’s book: The C++ Programming Language 4th Edition, it states:
Unless a formal argument (parameter) is a reference, a copy of the actual argument is passed to the function.
Passing by pointer is merely a technique that utilizes the properties of pointers to avoid the overhead of copying, rather than a passing method.
The Three Laws of Defining Copy/Assign and Destructor Functions
If a class requires a user-defined copy constructor, copy assignment operator, or destructor, it typically needs all three.
The compiler-generated implicit definitions of copy constructor and operator= have a memberwise copy semantic, so if the operations generated by the compiler cannot meet the class’s copying needs (for instance, if class members are handles managing some resources), using the compiler’s implicit definitions will lead to shallow copies, causing two objects to enter some shared state.
1 | struct A{ |
If the compiler-generated semantics are used, it would make objects x and y internally share a block of memory, so the user needs to define the copy constructor and copy assignment operator. For the same reason, when class members hold some resources, a user-defined destructor is also necessary.
Implementation of References
The C++ standard explains references like this:
[ISO/IEC 14882:2014 §8.3.2] A reference can be thought of as a name of an object.
However, the standard doesn’t require how this reference behavior should be implemented (which is often seen in the standard), but most compilers implement it using pointers in practice.
Consider the following code:
1 | int a=123; |
Then compiling it to LLVM-IR to see the actual behavior of the compiler:
1 | %2 = alloca i32, align 4 |
It’s evident that pointers and references have the exact same behavior post-compilation.
Appropriately Using Compiler-Generated Operations
In Implicit Declarations and Functions of Special Member Functions, it was mentioned that the compiler implicitly generates and defines the behavior of six kinds of special member functions.
Since the generated copy constructor and copy assignment operator both have a memberwise behavior, when the class we write can satisfy shallow copying (value semantics), there’s no need to write relevant operations at the expense, because the compiler-generated ones are just as good as your hand-written versions, and they are less error-prone.
1 | struct A{ |
Although when you haven’t explicitly defined a copy constructor and copy assignment operator, the compiler will implicitly define them, it’s still better to manually use =delete to specify.
The compiler-generated version is exactly the same as the hand-written:
1 | struct A{ |
It’s obvious that hand-writing is prone to error; this behavior can be safely handed over to the compiler.
Compressing Capacity and Truly Erasing Elements in STL Containers
Taken from C++ Programming Standards: 101 Rules/Guidelines and Best Practices Rule 82.
Compressing Container Capacity: The swap trick
1 | vector<int> x{1,2,3,4,5,6,7}; |
Truly Deleting Elements: std::remove does not perform the delete operation
The std::remove algorithm in STL does not truly remove elements from containers. As std::remove belongs to algorithm, it only operates over iterator ranges, not invoking container’s member functions, hence it cannot actually delete elements from containers.
Let’s take a look at the implementation in SGISTL (the implementation is a bit old and does not utilize std::move):
1 | template <class _InputIter, class _Tp> |
You can see they are merely moving elements’ positions, not actually deleting the elements; they simply move the elements that should not be deleted to the front of the container, then return the new ending position iterator.
Effectively, the deleted portion is moved to the back of the element, so to truly delete all matching elements from the container, the erase-remove idiom needs to be used:
1 | c.erase(std::remove(c.begin(),c.end(),value),c.end()); // Deletes elements at the tail of the container after std::remove |
Beware of Hiding Overloaded Functions in Base Classes
If there is a virtual function func in the base class but it also overloads several non-virtual functions:
1 | struct A{ |
If we want to use the non-virtual version of the func function inside a B object:
1 | B x; |
This is because when the derived class overrides the base class virtual function, it hides the other overloaded functions, which needs to be explicitly brought into scope in B:
1 | struct B:public A{ |
Macro Alternatives
Macros are replaced in the preprocessing stage, at which point C++’s syntax and semantic rules are not yet effective; thus, macros can only perform simple text replacement, making them extremely blunt tools.
Macros are almost never required in C++. You can define understandable constants using const and enum. Use inline to avoid the overhead of function calls, templates to specify series of functions and types, and namespaces to avoid name conflicts.
Unless used for conditional compilation, there is no legitimate reason to use macros in C++.
Class Memory Allocation Functions
In C++, memory allocation functions for classes are all static member functions:
Any allocation function for a class T is a static member (even if not explicitly declared static).
This means operator new/operator delete and operator new[]/operator delete[] are implicitly declared as static member functions.
Exception Safety
- Destructors, operator new, operator delete must not throw exceptions.
- Swap operations should not throw exceptions.
- First do anything that may throw exceptions (but will not change important states of the object), and then end with operations that will not throw exceptions.
- When an exception is thrown from a throw expression towards a catch clause, any function executing in the path must manage to clean up any resources they control before removing their activation record from the execution stack.
- Do not insert code that might cause an early return, calls to functions that might throw exceptions, or other actions that will prevent the resource release at the end of the function.
cv Versions of Pointers to Class Member Functions
If we have a class A with overloaded member functions func that differ only by whether the member function is const, how do we define a pointer to the member function separately?
1 | struct A{ |
If we just create a pointer to A::func, it points to the non-const version.
1 | void(A::*funcP)()=&A::func; |
To specify the const version, you must indicate const in the declaration:
1 | void(A::*funcConstP)()const=&A::func; |
For const A objects, use the const version, and for non-const A objects, use the non-const version; they cannot be mixed.
1 | const A x; |
Compare Operation Implementation in STL
Unlike C language macros, utilizing templates and predicates in C++ allows writing generic compare operations easily.
In a macro definition, care must be taken regarding parameter side effects, as macros are merely replacements, such as:
1 |
|
But this macro’s actual operation does not yield the behavior we expect.
Fortunately, in C++, we can avoid such ugly macro definitions using templates and also provide a custom predicate to realize our judgment behavior:
1 | struct Compare{ |
Computational Constructor
In certain cases, creating a constructor can improve the execution efficiency of member functions.
1 | struct String{ |
Using Members of Its Own Type
How can a member of a class access the current class type?
This can be written as follows:
1 | template<typename T> |
Though it has a somewhat forced feel…
Random Access in std::vector
std::vector allows random access because it overloads the [] operator and has at member function, thus typically we would have the following two ways:
1 | template<typename T> |
What are the differences between these two random access methods?
Sequential container’s
at(size_type)requires range checks.
[ISO/IEC 14882:2014] The member function at() provides bounds-checked access to container elements. at() throwsout_of_rangeif n >= a.size().
However, the standard doesn’t impose any requirements onoperator[].
Let’s take a look at some STL implementations (SGISTL) to see how std::vector implements operator[size_type] and at(size_type):
First, the implementation of at(size_type):
1 | // Implementation of at(size_type) |
Now look at the implementation of operator[](size_type):
1 | // Implementation of operator[](size_type) |
As you can see, there is no range check in the random access of operator[].
Thus the questions:
1 | x[0]; |
These two differ in that if x is non-empty, the behavior is the same; if x is empty, x.at(0) would throw an std::out_of_range exception (as required by C++ standards), while x[0] would lead to undefined behavior.
Note the Difference Between typedef and #define
1 | typedef int* INTPTR; |
Let’s directly see the IR code:
1 | %6 = alloca i32*, align 8 |
Note that %9 is not i32*, it’s an i32 object.
Because #define is merely a simple replacement at compile time, it expands during compilation as follows:
1 |
|
Thus, only i3 is of type int*, while i4 is of type int.
Why const Object Is Not a Compile-Time Constant?
1 | const int x=10; |
This is permissible; during compiler optimization, x will be replaced directly with 10.
The intermediate code is as follows:
1 | %6 = alloca i32, align 4 |
It can be seen that %7’s allocation does not use %6, hence it does not depend on x, and this object is known at compile-time.
However, consider when we write:
1 | int x; |
Here it’s because of compiler extensions, so C++ also supports VLA. But we can see that const cannot serve as a compile-time constant.
Class Query in Inheritance Hierarchies
In class inheritance hierarchies, several different derived classes may have the same base class; they might mutually inherit, resulting in several inherited levels. How do we check whether a certain derived class in a hierarchy inherits from a certain class?
We can use dynamic_cast to achieve our requirement. For an overview of C++ type conversions, you can check out my previous article: A Detailed Analysis of Type Conversions in C++. Here’s a description of dynamic_cast in the C++ standard (ISO/IEC 14882:2014):
The result of the expression
dynamic_cast<T>(v)is the result of converting the expression v to type T. T shall be a pointer or reference to a complete class type, or “pointer to cv void.” The dynamic_cast operator shall not cast away constness (5.2.11).
If C is the class type to which T points or refers, the runtime check logically executes as follows:
- If, in the most derived object pointed (referred) to by v, v points (refers) to a public base class subobject of a C object, and if only one object of type C is derived from the subobject pointed (referred) to by v, the result points (refers) to that C object.
- Otherwise, if v points (refers) to a public base class subobject of the most derived object, and the type of the most derived object has a base class of type C that is unambiguous and public, the result points (refers) to the C subobject of the most derived object.
- Otherwise, the runtime check fails.
The value of a failed cast to pointer type is the null pointer value of the required result type. A failed cast to reference type throws an exception (15.1) of a type that would match a handler (15.3) of type
std::bad_cast(18.7.2).
Thus, we can execute dynamic_cast conversion on class pointers in inheritance hierarchies to check the conversion success, hence determining whether a certain class exists in a derived class hierarchy.
Here’s a code example:
1 |
|
From the code above, you can see the inheritance hierarchy of the Circle class: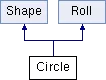
And the inheritance hierarchy of the Square class:
The above inheritance hierarchies are quite simple, but if we assume we are unaware of the specific inheritance hierarchies of Circle and Square, how do we determine whether Square contains a certain base class (like Roll)?
The solution, as mentioned above, is to utilize dynamic_cast! By converting to the class type that we want to check for in the hierarchy, if the conversion is successful, dynamic_cast returns a pointer converted from the source type to the target type; if it fails, it will return a null pointer (the reason for not using references is that we want to handle the potential threat of exceptions). This conversion is neither an upward nor downward conversion, but rather a lateral conversion. Hence, we need to check the object (pointer) returned by dynamic_cast to ascertain whether the detected type exists in the inheritance hierarchy.
However, I feel that this behavior applies only to very narrow scenarios and is rarely necessary in well-designed classes; if you feel overwhelmed by your class hierarchy, it is surely a poor design.
In list initialization, the initializer_list constructor takes precedence over the ordinary constructor
First, let’s introduce two basic concepts:
List-initialization is initialization of an object or reference from a braced-init-list. Such an initializer is called an initializer list.
initializer-list constructor: A constructor is an initializer-list constructor if its first parameter is of typestd::initializer_list<E>or reference to possibly cv-qualifiedstd::initializer_list<E>for some type E, and either there are no other parameters or else all other parameters have default arguments (8.3.6).
Note: Initializer-list constructors are favored over other constructors in list-initialization (13.3.1.7).
1 |
|
[ISO/IEC 14882:2014 13.3.1.7 Initialization by list-initialization] When objects of non-aggregate class type T are list-initialized (8.5.4), overload resolution selects the constructor in two phases:
- Initially, the candidate functions are the initializer-list constructors (8.5.4) of the class T and the
argument list consists of the initializer list as a single argument. - If no viable initializer-list constructor is found, overload resolution is performed again, where the
candidate functions are all the constructors of the class T and the argument list consists of the elements of the initializer list.
If the initializer list has no elements and T has a default constructor, the first phase is omitted. In copy-list-initialization, if an explicit constructor is chosen, the initialization is ill-formed. [ Note: This differs from other situations (13.3.1.3, 13.3.1.4), where only converting constructors are considered for copy-initialization. This restriction only applies if this initialization is part of the final result of overload resolution. - end note ]
In simpler terms, when the constructor parameters of a class are list-initialized, the overload resolution of the constructor is divided into two steps:
- First, it tries to match with the constructor whose parameter is an initializer-list. If the initializer-list has no elements and the class has a default constructor, this step is omitted.
- If no viable initializer-list constructor is found, overload resolution is performed again, with all constructors of the class as candidates, and the argument list consists of the elements of the initializer-list.
Note: In the context of copy list initialization (copy-initializer_list), if an explicit constructor is selected, the program becomes ill-formed.
1 | class A{ |
Moreover, explicit constructors will disable the implicit conversion of the initializer list.
1 | class A; |

