From C language to C++03, the OO features feel absolutely great. Recently, I focused on the new features of C++11 and found many fantastic syntactic sugars! It’s also very enjoyable to use.
List Initialization
List Initialization
As part of the C++11 standard, list initialization (using braces to initialize variables) has been comprehensively applied. This method is indeed very comfortable to use, for example, when initializing a vector template, you can either use a container to initialize it or initialize it to the value of N elements.
List initialization can prevent narrowing conversions, which means:
- If an integer type cannot store the value of another integer type, the latter will not be converted to the former. For example, char can be converted to int, but int cannot be converted to char.
- If a floating-point type cannot store the value of another floating-point type, the latter will not be converted to the former. For example, float can be converted to double, but double cannot be converted to float.
- Floating-point values cannot be converted to integer values.
- Integer values cannot be converted to floating-point values.
1 | // C++03 standard, constructor of containers |
The list initialization supported by C++11 standard:
The form of list initialization is C c{element-List}; or C c={element-List};
Note: Be sure to use braces; using parentheses for initialization has a completely different meaning.
When we use the auto keyword to deduce the type of a variable from an initializer, there’s no need to adopt the list initialization method. Moreover, if the initializer is a {} list, the deduced data type is definitely not what we want.
When using auto, do not use list initialization; using
=in auto is a better choice unless you are sure that it gives you the desired result.
1 | auto z1{99}; // z1's type is initializer_list<int> |
Additionally, when constructing objects of certain classes, there may be two forms:
- Providing a set of initial values.
- Providing several parameters.
Pay attention to the distinction between the following two expressions:
1 | // Be sure to distinguish these two meanings completely |
1 | int ival{10}; |
If the above code is compiled without adding std=c++11, four errors will occur:
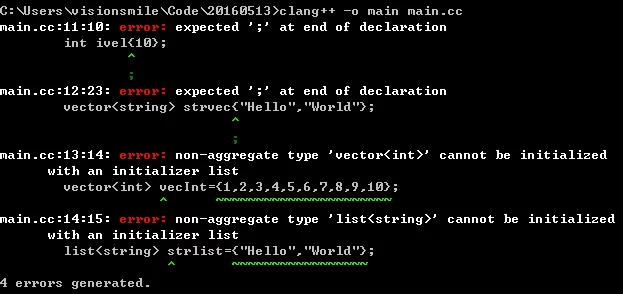
When using the C++11 standard, you have to add std=c++11, and compilation will not generate errors.
Run and output the initialized objects and containers above:
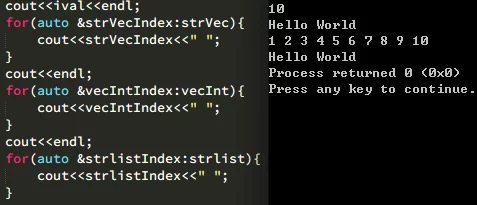
Initializer List
The new standard for C++ specifies using an initializer list enclosed in braces as the right operand of assignment statements.
1 | vector<int> intVec; |
List assignment statements cannot be used for narrowing conversions:
1 | int k; |
If the left operand is a built-in type, the initializer list can contain at most one value, and that value must not occupy more space than the target type space even if converted. The type conversion still refers to detailed analysis of type conversion in C++.
Regardless of the type of the left operand, the initializer list can be empty. In this case, the compiler creates a value-initialized temporary variable and assigns it to the left operand.
A list defined by {} can serve as an actual argument for the following parameter types:
- Type
std::initializer_list<T>, where the list values can implicitly convert to T. - Types that can be initialized by the values in the list.
- References to arrays of type T, where the list values can implicitly convert to T.
1 | template<class T> |
If ambiguity exists, functions with initializer_list parameters are preferred.
1 | template<class T> |
The reason for preferring functions with initializer_list parameters is that if selecting functions based on the number of elements in the list, the selection process can become quite confusing. During overload resolution, it is difficult to eliminate all potential ambiguities, but giving highest priority to initializer_list parameters when encountering {} list can minimize such conflicts.
Return Value of List Initialization
C++11 stipulates that functions can return a value list enclosed in braces.
From the concept of initializer list, it follows that if the list is empty, value initialization is performed on built-in types; otherwise, the returned value is determined by the function’s return type.
1 | vector<string> process(int x) { |
The result is: X > 0,Yes
List Initialization of Associative Containers
When defining a map, both the key type and value type must be specified; for a set, only the key type needs to be indicated, as there are no values in a set.
Each associative container has a default constructor that creates an empty container of the specified type. Associative containers can also be initialized as a copy of another container of the same type or from a range of values, as long as those values can be converted to the required container type.
Under the new standard, we can value-initialize associative containers:
1 | // Empty container |
Return Type of List Initialization Pair
Imagine a function needs to return a pair. Under the new standard (C++11), we can perform list initialization for the return value.
1 | pair<string, int> process(vector<string>& v) { |
If v is not empty, we return a pair composed of the last string in v and its size. Otherwise, we implicitly construct an empty pair and return it.
In earlier versions of C++, it was not allowed to use braces to return an object of type pair; the return value had to be explicitly constructed:
1 | if (!v.empty()) { |
nullptr Constant
Before C++11, literal 0 or NULL was used to initialize/assign a pointer to a null pointer.
NULL is a preprocessor variable defined in cstdlib, with a value of 0. When a preprocessor variable is used, it is automatically replaced by the preprocessor with the actual value, so initializing a pointer with NULL is the same as initializing it with 0.
Assigning an int variable to a pointer is an incorrect operation, even if the value of that variable happens to be 0.
1 | int *p1 = 0; // Initialize p1 with the literal value 0 |
The C++11 standard introduced the nullptr literal constant that can be used to initialize pointers to null.
nullptr is a special type of literal that can be converted to any other pointer type.
Using nullptr to initialize a pointer:
1 | int *p = nullptr; // Equivalent to int *p = 0; |
Note: Using uninitialized pointers is a significant cause of runtime errors. All pointers should be initialized, and a pointer should be immediately set to null after deletion; otherwise, accessing it again can lead to errors (dangling pointer).
constexpr
constexpr Variables
A constant expression (const expression) refers to an expression whose value does not change and can be computed during the compilation process.
Evidently, literals belong to constant expressions, while const objects initialized with constant expressions are also constant expressions.
Whether an object or expression is a constant expression is determined by its data type and initial value.
When constexpr appears in a function definition, it means “if a constant expression is given as a parameter, then the function should be usable in a constant expression.” When constexpr appears in an object definition, it indicates “evaluating the initializer at compile time.”
1 | const int MAX_NUM = 20; // MAX_NUM is a constant expression |
The C++11 standard stipulates that variables can be declared as constexpr types to allow the compiler to verify whether the value is a constant expression.
A variable declared as constexpr must be a constant and must be initialized with a constant expression.
1 | constexpr int ival = 20; // 20 is a constant expression |
constexpr Pointers
In a constexpr declaration, if a pointer is defined, the constexpr qualifier only applies to the pointer itself, not to the object it points to.
constexpr makes the pointer object top-level const (the pointer cannot be modified, while the object it points to can be modified).
1 | // p is a pointer to a constant integer; the pointer can be modified, but the object it points to cannot be modified |
constexpr Functions
A constexpr function is a function that can be used in constant expressions; the function must be simple enough to be evaluated at compile time.
The definition of a constexpr function is similar to others but must follow several regulations:
- The function’s return type and all parameter types must be literal types.
- The function body must contain only one return statement.
- No loops or local variables are allowed.
- constexpr should have no side effects (cannot write to non-local objects).
- Recursion and conditional expressions are allowed.
In other words, constexpr functions should be pure functions.
1 | int glob; |
1 | constexpr int new_sz() { return 42; } |
The compiler replaces calls to constexpr functions with their resulting values. To enable expansion during compilation, constexpr functions are implicitly specified as inline functions.
The body of a constexpr function can also include other statements, as long as those statements do not perform any operations at runtime.
Empty statements, type aliases, and using declarations are allowed in constexpr functions.
We allow the return value of constexpr functions to not be a constant:
1 | // If scale receives constant expressions as parameters, scale(const-parameter) is also a constant expression. |
When the argument of scale is a constant expression, its return value is a constant expression; otherwise, it is not.
1 | // Correct; the return value of scale(2) is a constant expression, and the compiler replaces the call to the scale function with the corresponding result value. |
A constexpr function does not necessarily return a constant expression.
1 | size_t i = 10; |
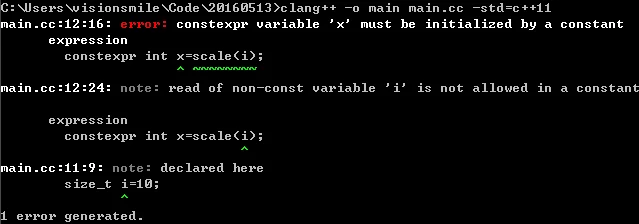
constexpr can return a reference or pointer:
1 | constexpr const int* addr(const int& r) { return &r; } // OK |
But this violates the intent of constexpr functions being evaluated as constant expressions.
Conditions outside of constexpr functions will not be evaluated at compile time, meaning they may request runtime evaluation.
1 | constexpr int check(int i) |
Constexpr Constructors
Compared with ordinary constexpr functions, constexpr constructors have distinctions: they are only allowed to perform simple member initialization operations.
Although constructors cannot be const (if the member function is const, it means the class’s internal data members cannot be modified), a constructor of a literal type can be a constexpr function.
A literal type must provide at least one constexpr constructor, which must be simple enough to qualify as constexpr, meaning its body must be empty, and all members must be potentially initialized with constant expressions.
Constexpr constructors can be declared as =default (compiler-synthesized default constructor) or =delete (deleted function). Otherwise, a constexpr constructor must meet both constructor and constexpr function requirements (which means the only executable statement it can have is a return statement).
Thus, the body of a constexpr constructor must be empty.
1 | class Debug { |
Constexpr must initialize all data members, with initial values using a constexpr constructor or through a constant expression.
Constexpr constructors are used to generate constexpr objects and the parameters or return types of constexpr functions:
1 | constexpr Debug io_sub(false, true, true); // Debugging IO |
For member functions, constexpr implicitly implies const.
1 | // No need to explicitly write const |
Address Constant Expressions
The addresses of global variables and statically allocated objects are constants. These addresses are assigned by the linker, not the compiler. Therefore, the compiler does not know the value of such address constants, limiting the use of pointer or reference types in constant expressions. For example:
1 | constexpr const char* p1 = "HelloWorld"; |
Type Deduction
C++11 introduced two methods of type deduction—auto and decltype, but they serve different purposes.
The role of auto: It deduces the type of the expression on the right side of the equals sign (the result).
The role of decltype: It obtains the type through existing expressions.
Important differences between decltype and auto:
- When decltype uses a variable expression, it returns the type of that variable (including const and references), while auto returns the type of the final result of the expression (ignoring top-level const attributes and applying type conversion).
- The result type of decltype tightly correlates with the expression form.
Auto Type Specifier
As a statically typed language, C++ requires us to know the variable’s type at the time of its definition.
1 | int ival = 10; |
C++11 introduced a new type specifier auto, which allows the compiler to analyze the type of the expression for us.
Unlike type specifiers that correspond to a specific type, auto allows the compiler to deduce a variable’s type from its initializer.
Note: A variable defined as auto must have an initializer.
When using the auto specifier to deduce type, sometimes it doesn’t match the initial type completely; the compiler makes appropriate adjustments to align with initialization rules. Refer to my blog article detailed analysis of type conversion in C++.
Note: Using reference types actually works with the object referenced, especially when set as an initializer; what participates in the initialization is actually the value of the referenced object.
1 | int ival_1 = 10; |
Auto generally ignores top-level const attributes, while keeping the bottom-level const intact.
1 | int i = 100; |
If you wish the deduced auto type to be a top-level const, you need to specify it explicitly:
1 | const auto f = ci; |
Setting a type as an auto reference retains the top-level const from the initializer.
1 | auto &g = ci; // g is a ref to a constant integer, bound to ci |
decltype Type Specifier
C++11 introduced the second type specifier, decltype, which serves to select and return the data type of the operand. During this process, the compiler analyzes the expression and determines its type without actually calculating the value of the expression.
1 | decltype(f()) sum = x; // sum's type is the return type of function f |
Decltype processes top-level const and references differently from auto.
If the expression used by decltype is a variable, then decltype returns that variable’s type (including const and references).
1 | const int ci = 0, &cj = ci; |
decltype and References
If the expression used by decltype is not a variable, then decltype’s return type corresponds to the result type of the expression.
1 | // The result of decltype can be a reference type |
If it’s a dereference operation, then decltype will get a reference type.
Dereferencing can access the object pointed to by the pointer and assign values to it. Thus, the result type of decltype(*p) is int& rather than int.
For decltype’s expressions, if the variable name includes parentheses, the result type will differ.
If the expression used by decltype is an unparenthesized variable, the result will be the type of that variable; if one or more layers of parentheses are added, the compiler treats it as an expression. A variable is a special kind of expression that can appear on the left side of an assignment statement, so such a decltype will yield a reference type.
1 | // If the expression for decltype is a variable with parentheses, the result will be a reference |
Simplifying Declarations with auto and decltype
1 | int ia[4][4]; |
With the introduction of auto and decltype, we can avoid adding a pointer type to the front of an array.
1 | // Output the value of each element in ia, with each inner array occupying a line |
Using string Objects as Filenames for File Stream Objects
1 | // Open file, each time write positioning to the end |
In earlier C++ standards, the filename parameter (that is, "out.txt" in the above code) was only allowed to be a C-style array.
In C++11, filenames can be both C-style arrays and string objects.
So, the above code can also be written as:
1 | string filename("out.txt"); |
STL Container Related Features
array and forward_list Containers
| Container Name | Meaning |
|---|---|
| array | Fixed-size array. Supports fast random access. Cannot add or remove elements. |
| forward_list | Singly linked list. Only supports unidirectional sequential access. Insert/delete operations at any position in the list are very fast. |
forward_list and array are new container types added in the C++11 standard.
Compared to built-in arrays, array provides a safer and easier-to-use array type.
Similar to built-in types, the size of array is fixed. Therefore, array does not support adding, deleting elements, or changing container size.
array is a template that can store any number and type of elements. It can also handle exceptions and const objects directly.
1 | array<int,3> x = {1, 2, 3}; |
Compared to built-in types, std::array has two obvious advantages:
- It is a real object type (supports assignment operations).
- It does not implicitly convert to a pointer to elements (passing an array degenerates to a pointer).
However, std::array also has downsides. We cannot deduce the number of elements based on the length of the initializer.
1 | // 3 elements |
More operations supported by std::array can be seen here: std::array - cppreference.
The design goal of forward_list is to achieve performance comparable to the best handmade singly linked list data structures.
Consequently, forward_list lacks a size operation, as maintaining or calculating its size would incur additional overhead compared to a handwritten list.
For other containers, size guarantees a fast constant time operation.
forward_listhas its own dedicatedemplaceandinsert.forward_listdoes not supportpush_backandemplace_backoperations.initializer_list Parameter
If the number of actual parameters for a function is unknown, but all actual parameters are of the same type, then you can use a parameter of type initializer_list.
initializer_list is a standard library type used to represent an array of values of a specific type. It is defined in the header file of the same name (initializer_list). Like vector, initializer_list is also a template type, and you must specify the type of the elements contained in the initializer_list when defining an initializer_list object.
| Operations Provided by initializer_list | Meaning |
|---|---|
| initializer_list |
Default initialization: empty list of type T |
| initializer_list |
lst has the same number of elements as initial values;lst’s elements are copies of corresponding initial values; elements in the list are const |
| lst2(lst)lst2=lst | Copying or assigning an initializer_list object does not copy the elements in the list; the original list and the copy share elements after copying |
| lst.size() | Number of elements in the list |
| lst.begin() | Get a pointer to the first element in lst |
| lst.end() | Get a pointer to the position after the last element in lst |
1 | template <class T> |
You can also use a braced-init-list {} to pass to the function with an initializer_list parameter:
1 | // Note: This code will produce an error under template <class T>, directly using initializer_list<string> will succeed |
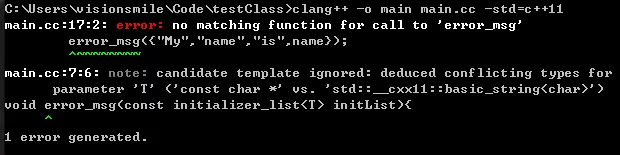
You can also use initializer_list to store existing variables of the same type and then pass them to a function:
1 | template <class T> |
A reference to an initializer_list object is a const reference, and obtaining a pointer to an initializer_list object is also a const pointer.
The following content is taken from cppreference——initializer_list:
An object of type std::initializer_list is a lightweight proxy object that provides access to an array of objects of type const T.
A std::initializer_list object is automatically constructed when:
- a braced-init-list is used in list-initialization, including function-call list initialization and assignment expressions
- a braced-init-list is bound to auto, including in a ranged for loop
Initializer lists may be implemented as a pair of pointers or pointer and length. Copying a std::initializer_list does not copy the underlying objects.
| Member Type | Definition |
|---|---|
| value_type | T |
| reference | const T& |
| const_reference | const T& |
| size_type | std::size_t |
| iterator | const T* |
| const_iterator | const T* |
From the table above, if we pass an initializer_list object using & or an iterator, we cannot modify its value.
By Value is possible, but the modified object will not be the actual parameter. #### Non-Member Function Swap for Containers
In C++11, containers provide both member function versions of swap and non-member function versions of swap.
Earlier standard versions only provided the member function version of swap. The non-member function version of swap is very important in generic programming. It is a good habit to uniformly use the non-member function version.
swap swaps the contents of two containers of the same type. After calling swap, the elements in the two containers will be exchanged.
1 | vector<string> svec1(10); // Vector with 10 elements |
Running result:

The operation of swapping the contents of two containers is guaranteed to be fast—elements themselves are not swapped; swap just exchanges the internal data structures of the two containers.
Except for array, swap does not perform any copy, delete, or insert operations on any elements; thus, it can be guaranteed to complete in constant time.
The fact that elements do not move means that, except for
string, iterators, references, and pointers pointing to the containers will not be invalidated after swap. They will still point to the elements they pointed to before the swap operation. However, after the swap, these elements belong to different containers now.
1 | vector<string> svec1{"My","name","is","zhalipeng"}; // Vector with 10 elements |
Note: Calling swap on a string container will cause iterators, pointers, and references to be invalidated.
Unlike other containers, swapping two
arraycontainers actually swaps their elements. Therefore, the time required to swap two arrays is proportional to the number of elements in the array.
Thus, forarraycontainers, after swap, the elements bound to pointers, references, and iterators remain unchanged, but their values have been swapped with the corresponding elements in the other array.
Return Type of Insert in Containers
We can use the member function insert of a container to insert a range of elements.
| Insert Version | Meaning |
|---|---|
| c.insert(p,t) | Creates an element with value t before the element pointed to by iterator p, returning an iterator to the newly added element |
| c.insert(p,b,e) | Inserts the elements in the range specified by iterators b and e before the element pointed to by iterator p |
| c.insert(p,n,t) | Inserts n elements with value t before the element pointed to by iterator p, returning an iterator to the first new element added; if n is 0, it returns p |
In the new standard, the insert version that accepts the number of elements or returns returns an iterator to the first newly added element. In older standards, these operations return void.
1 | vector<string> svec1{"My","name","is","zhalipeng"}; // Vector with 10 elements |
Emplace Operation
The new standard introduces three new members—emplace_front, emplace, and emplace_back, these operations construct rather than copy elements.
These operations correspond to push_front, insert, and push_back, allowing us to place elements at the front of the container, before a specified position, or at the end of the container.
forward_listhas its own dedicatedemplaceandinsertforward_listdoes not supportpush_backandemplace_backoperationsvectorandstringdo not supportpush_frontandemplace_front
When calling member functions push or insert, we pass an object of the element type to them, which is copied into the container. However, when we call an emplace member function, we pass the parameters to the constructor of the element type. Emplace members directly construct an element in the memory space managed by the container using these parameters.
For example:
1 | // Assume we now have a class test |
If we use emplace_back to add test objects:
1 | vector<test> x; |
Running result:
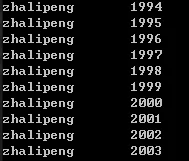
1 | // Let's try using push_back |
As you can see, the calls to emplace_back and push_back both create a new test object. When calling emplace, the object is created directly in the memory space managed by the container. While calling push_back creates a local temporary object and pushes it into the container.
The parameters of emplace functions vary based on the element type; the parameters must match the constructor of the element type.
1 | vector<test> x; |
String Numeric Conversion Functions
C++11 introduced several functions that can convert numeric data to and from standard library strings.
| Function | Operation Meaning |
|---|---|
| to_string(val) | A set of overloaded functions that returns the string representation of the numeric value val. val can be any arithmetic type. There is a corresponding version of to_string for each floating-point type and int or larger integer types. |
| stoi(s,p,b) stol(s,p,b) stoul(s,p,b) stoll(s,p,b) stoull(s,p,b) |
Returns the numeric value of the substring of s (representing integer content) starting at position p, with return types of int/long/long long/unsigned long/unsigned long long. b specifies the base used for conversion, default is 10. p is a pointer to store the index of the first non-numeric character in s, p defaults to 0, meaning the function does not store the index. |
| stof(s,p) stod(s,p) stold(s,p) |
Returns the numeric value of the substring of s (representing floating-point content), with return types of float/double/long double. The role of parameter p is the same as in integer conversion functions. |
1 | // to_string |
Running result:
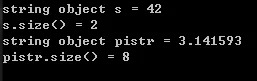
Converting double to string will result in floating-point rounding—see IEEE754 for details.
Converting from string to other arithmetic types:
1 | // stod |
Running result:
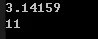
The above uses two member functions:
1 | // substr() returns a substring of the string starting at index and length num characters. If not specified, the default is string::npos. Thus, substr() simply returns the remainder of the string starting from index. |
Functions for Managing Capacity
| Member Function | Operation Behavior | Applicable Scope |
|---|---|---|
| c.shrink_to_fit() | Reduces capacity() to the same size as size() | Applicable only to vector, string, and deque |
| c.capacity() | How many elements c can hold without reallocating memory | Applicable only to vector and string |
| c.reserve(n) | Allocates enough memory space to hold at least n elements | Applicable only to vector and string |
The reserve operation does not change the number of elements in the container; it affects how much memory space vector preallocates.
Only when the required memory space exceeds the current capacity will a reserve call change the capacity of a vector. If the required size is greater than the current capacity,
reserveallocates at least the same amount of memory space as the requirement (possibly larger).If the required size is less than or equal to the current capacity,
reservedoes nothing. Especially when the required size is less than the current capacity, the container does not free memory space, so after calling reserve, the capacity will be greater than or equal to the parameter passed to reserve.Thus, calling reserve will never reduce the memory space the container occupies.
Similarly, the resize member function changes only the number of elements in the container and not the capacity of the container. Thus, resize cannot be used to reduce the reserved memory space of the container.
In the C++11 standard, we can call shrink_to_fit to request vector, deque, or string to release unused memory space.
This function indicates that we no longer need any extra memory space. However, the specific implementation may choose to ignore this request, meaning that calling shrink_to_fit does not guarantee the return of memory space.
Difference between Capacity and Size
- size: Refers to the number of elements currently stored in the container
- capacity: Refers to how many elements can be stored without reallocating memory
1 | vector<int> x; |
The code above yields different results under different compilation environments:
| Compilation Environment | Result |
|---|---|
| Visual Studio2015 | 0 0 |
| Clang 3.7.0 x86_64-w64-windows-gnu | 0 0 |
| g++ 5.2.0 x86_64-posix-seh-rev1 | 0 0 |
Unordered Containers
C++11 defines four unordered associative containers.
These are: unordered_map, unordered_set, unordered_multimap, unordered_multiset. When using the corresponding unordered containers, you also need to include the respective header files (container names).
These containers do not organize elements using comparison operators but use a hash function and the == operator for the keyword type. Unordered containers are very useful when elements of the keyword type do not have a clear sequence relationship. In some applications, maintaining the sequence of elements can be very costly, making unordered containers very useful.
If the keyword type is inherently unordered, or performance testing reveals issues that can be solved through hashing techniques, unordered containers can be used.
Using Unordered Containers
In addition to hashing management operations, unordered containers provide the same operations as ordered containers (find, insert, etc.). This means that the operations usable on map and set can also be used on unordered_map and unordered_set. Similarly, unordered containers also have versions that allow duplicate keywords.
Generally, an unordered container can replace its corresponding ordered container and vice versa. However, since elements are not stored in order, the output of a program using an unordered container will often differ from that of the ordered container version.
For example, you can write a word count program using unordered_map:
1 | unordered_map<string,size_t> word_count; |
Note that because it is an unordered container, the order of the output is unlikely to follow the order of input.
Managing Buckets
Unordered containers are organized in storage as a group of buckets, with each bucket storing zero or more elements. Unordered containers map elements to buckets using a hash function. To access an element, the container first calculates the hash value of the element, which indicates which bucket to search in. The container keeps all elements with a specific hash value in the same bucket. If the container allows duplicate keywords, all elements with the same keyword will also reside in one bucket. Thus, the performance of unordered containers depends on the quality of the hash function and the count size of the buckets.
For the same parameters, a hash function must always produce the same result. Ideally, the hash function should also map each specific value to a unique bucket. However, mapping different keywords to the same bucket is also permissible.
When a bucket holds multiple elements, a sequential search for those elements must be conducted to find the one we want. Calculating a uniform hash value and searching within a bucket are generally fast operations. However, if a bucket holds many elements, finding a specific element requires numerous comparison operations.
Unordered containers provide a set of functions to manage buckets. These member functions allow us to query the status of the container as well as force the container to restructure when necessary.
| Functions for Managing Buckets | Operation Meaning |
|---|---|
| Bucket Interface | |
| c.bucket_count() | The number of buckets currently in use |
| c.max_bucket_count() | The maximum number of buckets the container can hold |
| c.bucket_size(n) | The number of elements in the nth bucket |
| c.bucket(k) | Which bucket contains the elements with the keyword k |
| Bucket Iterators | |
| local_iterator | Iterator type used to access elements in buckets |
| const_local_iterator | Const version of the bucket iterator |
| c.begin(n)/c.end(n) | Iterate over the first element and the end after for the nth bucket |
| c.cbegin(n)/c.cend(n) | Similar to the previous two functions, but returns const_local_iterator |
| Hash Strategy | |
| c.loadfactor() | The average number of elements per bucket, returns a float value |
| c.max_load_factor() | c attempts to maintain the average bucket size, return float values. c will add new buckets when necessary to ensure that load_factor <= max_load_factor and restructure storage so that bucket_count >= n |
| c.rehash(n) | Restructure the storage, ensuring that bucket_count >= n and bucket_count > size/max_load_factor |
| c.reserve(n) | Restructure the storage to allow c to hold n elements without needing to rehash |
Requirements for Keyword Types in Unordered Containers
By default, unordered containers use the == operator of the keyword type to compare elements, and they also use an object of type hash<key_type> to generate the hash value for each element. The standard library provides hash templates for built-in types (including pointers). Hashes have also been defined for some standard library types, including string and smart pointer types, allowing us to directly define unordered containers with keywords of built-in types (including pointer types), string, or smart pointer types.
Note: While unordered containers support keywords of built-in types (including pointer types),
string, orsmart pointer types, we cannot directly define unordered containers with custom types as keywords.Unlike containers, you cannot directly use the hash template and must provide your own hash template version. This will be discussed in the section on
template specialization.
We do not use the default hash but instead use another method, similar to overloading the default comparison operation for the keyword type in ordered containers.
To allow our custom type to act as a keyword for unordered containers, we need to provide functions that replace the == operator and the hash calculation function.
1 | // Assume we now have a custom class book |
You can start defining these overloaded functions:
1 | size_t hasher(const book &bk){ |
If we do not overload the == operator of the class:
1 | using BK_multiset=unordered_multiset<book, decltype(hasher)*,decltype(eqOq)*>; |
If we have overloaded the == operator:
1 | unordered_set<book,decltype(bkHash)*> bkset(10,bkHash); |
Lambda Expressions
We can pass any category of callable object to an algorithm.
An object or expression is considered callable if the call operator () can be applied to it.
Before C++11, the callable objects we could use were functions, function pointers, and classes that overload the call operator.
C++11 introduced a new callable object—lambda
A lambda expression represents a callable code unit. We can think of it as an unnamed inline function.
Lambda expressions are also known as anonymous functions.
Like any function, a lambda has a return type (must use trailing return type), a parameter list, and a function body.
However, unlike a function, a lambda may be defined within a function.
1 | [capture list](parameter list)-> return type{function body} |
The capture list is a list of local variables defined in the enclosing function that the lambda will use. The parameter list, return type, and function body are similar to those of ordinary functions.
You can also omit the lambda’s parameter list and return type; omitting the parentheses and parameter list is equivalent to specifying an empty parameter list. However, you must always include the capture list and function body. If the return type is omitted, the lambda deduces its return type from the code in the function body. If the function body is just a return statement, the return type is deduced from the returned expression’s type; otherwise, the return type is void.
1 | auto f=[]{return 42;}; |
If the function body of a lambda includes anything other than a single return statement (C++14 allows multiple as long as they are the same type) and the return type is not specified, then the return type will be void.
Note: Lambdas can not only be passed as parameters but can also be used to initialize a variable declared as auto or std::function<R(AL)>, where R is the return type and AL is the argument list type.
1 | // error, cannot infer the type of an auto variable before using it (recursion) |
If you just want to give a lambda a name without recursive usage, you can use auto.
If a lambda captures nothing, it can be assigned to a pointer to the correct type of function.
1 | double (*p1)(double)=[](double a){return sqrt(a);}; |
Passing Parameters to Lambda
Similar to an ordinary function, actual parameters provided when calling a lambda are used to initialize the lambda’s formal parameters.
Generally, the types of the actual parameters must match those of the formal parameters. However, unlike ordinary functions, lambda cannot have default parameters; hence, the number of actual parameters must match the number of formal parameters. Once the formal parameters are initialized, the function body can be executed.
1 |
|
Executing result:
The prototype of stable_sort: For more detailed content, refer here——stable_sort - cppreference
1 | // Parameters first and last indicate elements in the range, comp is a predicate parameter which is a comparison function, returning true if the first parameter is less than the second parameter |
Thus, we can use lambdas to replace the cmp function (after all, lambda is a form of function, but it’s an anonymous function).
Using Capture Lists
Predicate
Before introducing the lambda capture list, let’s get familiar with the concept of a predicate.
A predicate is a callable expression whose result is a value that can be used as a condition (bool).
Standard library algorithms use two types of predicates: unary predicates (meaning they can accept a single parameter) and binary predicates (meaning they can accept two parameters). Algorothems accepting predicate arguments call the predicate on the elements in the input sequence, so the element type must be convertible to the predicate parameter types.
While a lambda can appear inside a function, using its local variables, it can only use those variables that are explicitly specified. A lambda indicates which variables it will use by including them in its capture list. The capture list gives the lambda the information needed to access the local variables.
1 | int num=5; |
In the above code, the lambda will capture num to use in the lambda body.
Let’s rewrite the above code to output all the elements in a container of length greater than X.
1 | for (auto index = find_if(word.begin(), word.end(), [num](const string& a) {return a.size() >= num; }); index != word.end();) { |
Running result:
Lambda Capture and Return
When a lambda is defined, the compiler generates a new (unnamed) class type corresponding to the lambda.
When passing a lambda to a function, a new type and an unnamed object of that type are defined simultaneously: the passed parameter is an unnamed object of the class type generated by this compiler.
When we define a variable initialized by a lambda with auto, we define an object of the type generated from the lambda.
By default, classes generated from lambdas include a data member corresponding to the local variables captured by the lambda. Like any ordinary class data members, the data members of a lambda object are initialized when the lambda object is created.
The choice between value capture and reference capture is based on the same criteria as function parameters.
If we want to write to a captured object, or the captured object is large, we should use references. For lambda, we should also be cautious that its lifetime may exceed that of its caller.
When passing a lambda to other threads, generally, value capture ([=]) is preferable: accessing the stack contents of other threads through references or pointers is a dangerous operation (for correctness and performance), and more seriously, viewing the content of a terminated thread’s stack may lead to errors that are hard to detect.
If you want to capture variadic templates, you can use ...:
1 | template<typaname ...Var> |
Value Capture
Like parameter passing, the capture method of variables can be either by value or by reference.
Similar to passing by value parameters, the precondition for value capture is that the variable can be copied. Unlike parameters, the captured variable’s value is copied when the lambda is created, not when called.
1 | int x=11; |
Note: Using value capture does not allow you to directly modify the captured variable’s value in the lambda.
If we intend to modify the value of the object captured by value, it will result in a compilation error, whereas reference capture will not:
1 | // Value capture |
If you want to modify a value captured object within the lambda’s function body, you can use reference capture, or you can use the mutable keyword on a value-captured lambda, which will be introduced later, but we’ll leave it aside for now.
cppreference states this:
Unless the keyword
mutablewas used in the lambda-expression, the function-call operator is const-qualified and the objects that were captured by copy are non-modifiable from inside this operator().
Link: Lambda functions (since C++11)
Reference Capture
We define a lambda using reference capture, capturing variables by adding an & sign before them.
1 | int x=11; |
Reference capture and returning references have the same problems and limitations: if we capture a variable via reference, we need to ensure the referenced object exists at the time the lambda executes.
Lambdas capture only local variables, and these variables are no longer valid after the function ends. If a lambda may execute after a function ends, a reference to a captured variable will have disappeared.
Reference capture can sometimes be necessary, for instance, when we need to capture an ostream since IO objects cannot be copied, and thus must be captured by reference.
You can also return a lambda from a function. A function can directly return a callable object or return a class object that contains callable objects as data members. If a function returns a lambda, like a function that cannot return a reference to a local variable, this lambda also cannot contain reference captures.
Implicit Capture
In addition to explicitly listing the variables we want to use from the containing function, we can also allow the compiler to infer which variables to use based on the code inside the lambda body (meaning the compiler will only capture the variables that are used in the function body). To indicate that the compiler should infer the capture list, either & or = should be written in the capture list. & indicates that the compiler should use capture by reference, while = indicates capture by value.
1 | int ival = 11; |
We can also use a mixed capture method, applying one capture method to some variables while applying another capture method to others.
1 | int ival = 11; |
When we mix implicit captures and explicit captures, the first element in the capture list must be either & or =. This symbol specifies the default capture mode as reference or value.
When mixing implicit captures and explicit captures, the explicitly captured variables must use a different method from the implicit captures. That is, if the implicit capture method is value capture, then the explicitly captured variables must use reference capture, and vice versa.
Various Capture Methods of Lambda
| Capture Method | Meaning |
|---|---|
| [] | Empty capture list. Lambda cannot use variables from the containing function. A lambda can only use captured variables after they are captured. |
| [names] | names is a comma-separated list of names, all of which are local variables from the containing function. By default, the variables in the capture list are copied. If & is used before a name, it indicates capture by reference. |
| [&] | Implicit capture list. Uses capture by reference. All entities used in the lambda body from the containing function are accessed by reference. |
| [=] | Implicit capture list. Uses capture by value. The lambda body will copy the values of the entities used from the containing function. |
| [&,identifier_list] | identifier_list is a comma-separated list containing zero or more variables from the containing function. These variables are captured by value, while any implicitly captured variables are captured by reference. The capture list can include this. Names in identifier_list cannot use & before them. |
| [=,identifier_list] | Variables in identifier_list are captured by reference, while any implicitly captured variables are captured by value. Names in identifier_list cannot include this, and must be preceded by &. |
Lambda Capturing this in Member Functions
When a lambda is used inside a member function, how can we access members of the class? We can add this to the capture list, making the class members available in the set of captured names.
1 | class Request { |
Members are captured by reference, which means that [this] signifies that members are accessed via this and not copied into the lambda.
[this] is incompatible with [=], so a slight oversight may cause race conditions in multi-threaded programs.
Mutable Lambda
By default, a lambda will not change the value of a variable that has been captured by copy.
If we wish to change the value of a captured variable, we must add mutable after the parameter list. Thus, a mutable lambda can omit the parameter list.
For reference captures, there’s no need to explicitly add the mutable keyword after the parameter list, but it is certainly required for value capture.
1 | int ival = 11; |
However, a lambda that uses value capture must use mutable.
1 | int ival = 11; |
Whether a variable captured by reference in a lambda can be modified depends on whether this reference points to a const type or a non-const type.
1 | const int ival = 11; |
The same issue applies to value capture:
1 | const int ival = 11; |
So, the type of an object captured by value is exactly the same as that of the function’s local variable.
Specifying the Return Type of Lambda
By default, if a lambda body contains any statement other than return, the compiler assumes this lambda returns void. Similar to other void functions, a lambda that is inferred to return void cannot return a value.
The return type of a lambda expression can be inferred from the lambda expression itself, which ordinary functions cannot do.
If the body of a lambda contains only a single return statement, then the return type of this lambda is the type of that return expression. (In C++14, it is possible to have multiple return statements without explicitly specifying the type, as long as it is guaranteed that each return returns the same type, see further details later).
First, recognize the following forms of lambda definitions:
| Syntax |
|---|
| [ capture-list ] ( params ) mutable(optional) exception attribute -> ret { body } |
| [ capture-list ] ( params ) -> ret { body } |
| [ capture-list ] ( params ) { body } |
| [ capture-list ] { body } |
| Explanation | Effect |
|---|---|
| mutable | allows body to modify the parameters captured by copy, and to call their non-const member functions |
| exception | provides the exception specification or the noexcept clause for operator() of the closure type |
| attribute | provides the attribute specification for operator() of the closure type |
| capture-list | a comma-separated list of zero or more captures, optionally beginning with a capture-default. Capture list can be passed as follows (see below for the detailed description): **[a,&b]** where a is captured by value and b is captured by reference. **[this]** captures the **this** pointer by value **[&]** captures all automatic variables odr-used in the body of the lambda by reference **[=]** captures all automatic variables odr-used in the body of the lambda by value **[]** captures nothing |
| params | The list of parameters, as in named functions, except that default arguments are not allowed (until C++14). If auto is used as a type of a parameter, the lambda is a generic lambda (since C++14) |
| ret | Return type. If not present it’s implied by function return statements (or void if it doesn’t return any value) |
| body | Function body |
Consider the following code:
1 | // Transform all values in a sequence to their absolute values |
Execution result:
The transform algorithm is defined in the algorithm header file, and its function prototype is as follows:
1 | template< class InputIt, class OutputIt, class UnaryOperation > |
In the code above, we passed a lambda to transform that returns the absolute value of its parameter. The body of the lambda is a single return statement that returns the result of an expression, so we don’t need to specify the return type, as it can be inferred from the conditional operator.
However, if we use an apparently equivalent if statement, it will produce an error:
1 | // Incorrect usage in C++11; it doesn't support implicit deduction of multiple return expressions |
However, I did not get any errors when compiling with clang++ and g++. (WTF).
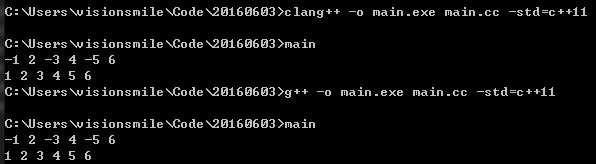
Upon researching, I found: Lambda functions (since C++11) - cppreference and C++14 Language Extensions.
C++11 permitted automatically deducing the return type of a lambda function whose body consisted of only a single return statement:
1 | // C++11 |
This capability was expanded in two ways. First, it now works even with more complex function bodies containing more than one return statement, as long as all return statements return the same type:
1 | // C++14 |
Second, it now works with all functions, not just lambdas:
1 | // C++11, explicitly named return type |
Of course, this requires the function body to be visible.
Finally, someone will ask: “Does this work for recursive functions?” The answer is yes, as long as a return precedes the recursive call.
See also:
- [N3638] Jason Merrill: Return type deduction for normal functions.
In summary:
C++14 can have multiple return expressions without using trailing return (multiple return), but the types of these return values must be the same.
However, C++11 does not have this property, so I suspect it might be a bug in the compiler…
Parameter Binding
For simple operations that are only used in one or two places, lambda expressions can be used. However, if we need to use the same operation in many places, it is often better to define a function instead of rewriting the same lambda expression multiple times.
If the capture list of a lambda is empty, a function can usually substitute it.
For example, in the sample code used to introduce lambdas:
1 | int num = 5; |
We can implement it using either a lambda (as shown above) or by defining a function:
1 | bool check_size(const string &s, string::size_type sz) { |
However, we cannot use this function as a parameter to find_if. As introduced in lambdas, find_if requires a “unary predicate” parameter, meaning the given parameter must accept a single argument. To replace the lambda with check_size, we need to solve the problem of how to pass a parameter to the sz parameter.
1 | // The calling form of check_size |
Standard Bind Function
By using the bind function, we can resolve the issue of passing a length parameter to check_size.
The bind standard library function is defined in the functional header file. You can think of the bind function as a generalized function adapter, creating a new callable object to “adapt” the parameter list of the original object.
The general form to call bind is:
1 | auto newCallable = bind(callable, arg_list); |
Here, newCallable itself is a callable object, and arg_list is a comma-separated list of parameters corresponding to the parameters of the given callable. That is, when we call newCallable, it will call callable and pass the parameters specified in arg_list.
The parameters in arg_list may contain names like _n, where n is an integer. These are “placeholders” representing the parameters of newCallable, occupying the positions of the parameters passed to newCallable. The number n indicates the position of the parameter in the generated callable object: _1 represents the first parameter of newCallable, _2 represents the second parameter, and so on.
Using Placeholders
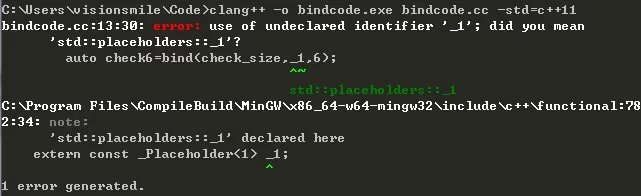
Note: The names _n are defined in a namespace called placeholders, which itself is defined in the std namespace.
So when we use _1, _2, etc. in bind, we must use the std::placeholders namespace:
1 | // All names in this namespace can be used in the program |
Otherwise, there will be a compile error:
Binding Parameters with Bind
By binding the sz parameter of check_size via bind, we generate a unary predicate that accepts a single parameter.
As mentioned earlier, we need to pass check_size, which accepts two parameters, to a function that must accept a unary predicate, so we need to generate an object that invokes check_size via bind.
1 | // check6 is a callable object that accepts a string type parameter |
This bind call only has one placeholder, indicating that check6 accepts a single parameter. The placeholder appears in the first position of arg_list, signifying this parameter corresponds to the first parameter of check_size. This parameter is a const string&. Thus, calling check6 must involve passing a string-type parameter to it, and check6 will pass this parameter to check_size.
1 | string s = "hello"; |
Using gprof, we can see that check_size was called once.
1 | % cumulative self self total |
With bind, we can replace the original lambda-based find_if call:
1 | auto wc = find_if(words.begin(), words.end(), [sz](const string& a) { return a.size() >= sz; }); |
With the version that uses check_size:
1 | auto wc = find_if(words.begin(), words.end(), bind(check_size, _1, sz)); |
This bind call generates a callable object that binds the second parameter of check_size to the value of sz. When find_if calls this object on each string in words, it will invoke check_size, passing the given string and sz to it. Thus, find_if can effectively compare the size of each string with sz in the input sequence.
Bind Parameter Details
As previously mentioned, we can use bind to fix the values of parameters. More generally, bind can also be used to bind parameters in callable objects or rearrange the order of their parameters.
For instance, if f is a callable object with five parameters, then the following call to bind:
1 | auto g = bind(f, a, b, _2, c, _1); |
The above code will generate a callable object with two parameters, represented by placeholders _1 and _2. This new callable object will pass its parameters as the third and fifth parameters to f. The first, second, and fourth parameters of f are bound to the given values a, b, and c respectively.
The parameters passed to g will be bound to the placeholders according to their positions. Thus, when we call g, its first parameter will be passed to f as the last parameter, and the second parameter will be passed as the third parameter.
In effect, this call will map g(_1, _2) to f(a, b, _2, c, _1). That is, a call to g will invoke f with g’s parameters replacing the placeholders, plus the bound parameters a, b, and c. For example, calling g(X,Y) would result in invoking f with parameters a, b, Y, c, X.
Using Bind to Rearrange Parameter Order
Note: sort is defined in the algorithm header file and must be included before use.
We can use sort to order the contents of a container, first defining a binary predicate.
1 | bool isShorter(const string& s1, const string& s2) { |
We can use sort to order a vector
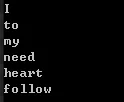
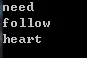
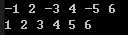
1 | vector<string> words{"I", "need", "to", "follow", "my", "heart"}; |
The result is:
1 | I to my need heart follow |
The sort result is ordered in ascending, but what if we want it in descending order? Can we simply modify the implementation of isShorter?
Not necessarily, we can use bind to reorder the parameters to achieve this.
1 | // Switch the first parameter of the sort predicate to be the second parameter of isShorter |
The result will be:
1 | follow heart need to my I |
Binding Reference Parameters (ref(_n))
By default, parameters that are not placeholders in bind are copied into the callable object returned by bind. However, similar to lambda, we hope to pass some bound parameters by reference, or the type of the parameter we want to bind cannot be copied (I/O objects cannot be copied or assigned).
For example, to replace a captured ostream (which cannot be copied) with a lambda:
1 | // os is a local variable, referencing an output stream |
We can easily write a function to perform the same task:
1 | ostream& print(ostream& os, const string& s, char c) { |
However, we cannot directly use bind to replace the capture of os:
1 | // Error, cannot copy os |
The reason is that bind copies its parameters, and we cannot copy an ostream. If we want to pass an object to bind without copying it, we must use the standard library ref function:
1 | for_each(words.begin(), words.end(), bind(print, ref(os), _1, ' ')); |
The ref function returns an object that contains a given reference, and this object is copyable. The standard library also has a cref function that generates a class that holds a const reference.
Backward Compatibility: Parameter Binding
Older versions of the standard library (before C++11) defined two functions named bind1st and bind2nd. Similar to bind, these two functions accept a function as a parameter and generate a new callable object that calls the given function and passes the bound parameter to it. However, these functions can only bind the first or second parameter, respectively. Due to their limitations, these functions have been deprecated in the new standard. The term deprecated means that the feature is no longer supported in newer versions. In new C++ programs, bind should be used.

