C++ Basic Syntax Concepts Organization.
Quick Start with C++
Most of the basic elements of C++: built-in types, library types, class types, variables, expressions, statements, functions.
Main Function
main function: Every C++ program must contain a main function, there is only one main function, and the main function is the (only) function explicitly called by the operating system.main function's return value:
- The main function determines whether the program has successfully completed execution through its return value. A return value of 0 indicates that the program has successfully completed execution.
- The return value of the main function is a
status indicator. Any othernon-zero return valuehas a meaning defined by the operating system. Typically, a non-zero return value indicates that an error has occurred.- The return value of the main function must be of type int, which represents an integer.
main function prototype:
int main(
void)
int main(int argc,char** argv)
Source File Naming Convention
Program file is called a source file. The file extension indicates that the file is a program. The file extension usually also indicates what language the program is written in and which compiler is chosen to run.
A Glimpse into Input/Output
C++ does not directly define any statements for input or output (IO), this functionality is provided by the standard library.
Handling formatted input and output is done by the iostream library. The foundation of iostream is two types named istream and ostream. iostream is derived from istream and ostream, here we just do a basic understanding, detailed content of the standard IO library will be elaborated in Chapter 8.
Standard Input and Output Objects
The standard library defines 4 IO objects.
Buffered standard input (cin): Handles input using theistreamtype object namedcin(pronounced see-in).
cinis a buffered stream.
Data input from the keyboard is stored in a buffer, and when extraction is needed, data is taken from the buffer.
If too much data is entered at once, it will remain there to be used gradually; if an error is made, it must be corrected before hitting enter, as after the enter key is pressed, it cannot be undone (cin will flush the buffer). New data cannot be requested until all the data in the input buffer is consumed. It is impossible to clear the buffer using a flush, so you cannot input incorrectly or excessively!
Buffered standard output (cout): Handles output using theostreamtype object namedcout(pronounced see-out).
coutdisplays output on the terminal, and thecoutstream has abufferin memory to store data in the stream. When anendlis inserted into thecoutstream, regardless of whether the buffer is full (flush the buffer), all data in the stream is immediately output, followed by inserting anewline character.
Unbuffered standard error (cerr): Generally used to output warning and error messages to the program users (pronounced see-err).No buffering, content sent to it is output immediately.Buffered standard error (clog): Used to produce general information about program execution (pronounced see-log).
The difference between clog and cerr: The difference lies in that cerr outputs information directly to the display without buffering, while clog’s information is stored in a buffer and only outputs when the buffer is full or encounters endl.
In C++, cin, cout, cerr and C’s stdin, stdout, stderr are all synchronized, meaning that the iostream objects and C’s stdio streams are synchronized, and their synchronization relationships are as follows: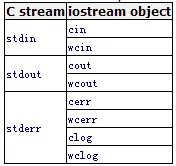
Synchronization indicates that we can mix cout and printf or other corresponding streams in our programs.
std::ios_base::sync_with_stdio(false) can be used to cancel this synchronization, after which cout and printf will not output in the expected order in the following program:
1 | std::ios_base::sync_with_stdio(false); // Disable stream synchronization |
Output:
2 2 2 2 2 2 2 2 2 2
Removing the std::ios_base::sync_with_stdio(false); line of code or changing it to true (enabling stream synchronization) results in:
1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2
Because of this synchronization, cin and cout are slower than scanf and printf. If we add std::ios_base::sync_with_stdio(false) before using cin and cout, their speed will actually be similar to scanf and printf.
Reference articles:
C/C++ Input/Output Buffer
Exploring the Fastest File Read Solutions in C++
What is flushing the buffer?
When opening a file in a buffered way and writing a few bytes to it, generally these bytes will not be immediately written to the file, only when the buffer is full will they actually be written to disk. To save data before the buffer is full, a flush buffer operation (endl) can be performed.
The following actions trigger a flush buffer:
- When the buffer is full;
- When line output encounters endl, cerr, or cin;
- Executing a flush function;
- Closing the file.
Input and Output Operators
Output operator (<< operator) AND Input operator (>> operator)endl: Can only be used in output (cout<<"HelloWorld"<<endl but cannot be used in (cin>>ival>>endl). endl is a special value called a manipulator, writing it into the stream has the effect of newline and flushing the buffer associated with the device. By flushing the buffer, the user can immediately see the output that has been written to the stream.
Note: Output statements inserted during debugging should refresh the output stream. Forgetting to flush the output stream may cause output to remain in the buffer, leading to erroneous judgments about the crash location if the program crashes.
Expressions
Expressionsare composed ofoperatorsandoperands.Operandsare the objects being operated on by theoperators.Note: Expressions have no semicolon; adding a semicolon after the expression turns it into a statement.Operandscan beconstants,variables, orcombinations of both.
Some expressions are composed of multiple smaller expressions, and these smaller expressions are calledsub-expressions.
Every expression has a value, and the system performs operations according to the order described by the operator precedence.
About Comments
*
Comments: Comments can help others read the program better, usually summarizing the algorithm, confirming the purpose of variables, or clarifying difficult-to-understand code segments. Comments do not increase the size of the executable program; the compiler ignores all comments.*
There are single-line comments and paired comments in C++.
- Single-line comments: Start with a double slash (//), and the content to the right of the double slash on a line is a comment.
- Paired comments: The comment pair is inherited from C language. Paired comments start with “
/*and end with “*/“. The compiler considers all content that falls between the comment pair “/**/“ as a comment.
Comments are allowed wherever there can be tabs, spaces, or newline characters. Paired comments can span multiple lines.
- Paired comments are typically used for multi-line explanations.
- Double slash comments are commonly used for marking half-lines or single lines (putting // at the start of the line).
- Incorrect comments are worse than no comments.
Note: Paired comments cannot be nested. A paired comment always starts with /* and ends with */. One paired comment cannot appear within another paired comment.
Control Structures
While Statement
whileprovides the functionality for iterative execution (loop execution).while structure format: while(condition)while_body_statement;whilerepeatedly executes the relatedwhile_body_statementby testing theconditionuntil the condition is false (false).
Condition is an evaluable expression, so its result can be tested.
If the result value is non-zero, then the condition is true (true). If the value is zero, then the condition is false (false).The condition must have a termination condition (the condition value should gradually approach the termination value (false) during the loop), otherwise, it enters an infinite loop.
For Loop
For loop structure format:
for(initialize;Condition;count)for_body_statement;initializeandcountcan be omitted, but there must be an expression in the function body that causes the Condition to approach the termination condition.
Note: Variables created in varName or within the function body cannot be accessed after the loop ends. Because these variables are already destroyed by the end of the loop.
If Statement
If statement structure format:
if(
condition){true_body_statement;
}else{else_body_statement;
}
Ifconditionis true, then executetrue_body_statement;.
Ifconditionis false, then executeelse_body_statement;.
Note: In an if statement, true_body_statement and else_body_statement will never execute simultaneously (only one can execute).
Reading an Unknown Number of Inputs
1 |
|
In this loop, the istream object is used as a condition, the result tests the state of the stream. If the stream is valid (it is possible to read the next input), then the test succeeds.
When encountering an end-of-file (EOF) or invalid input (such as reading a non-integer value (because value is of int type)), the istream object becomes invalid.An istream object in an invalid state will cause the condition to fail.
The test will succeed and the while loop will execute until an end-of-file (or some other input error) is encountered.
Input from the keyboard for end-of-fileWindows: Ctrl + ZUnix: Ctrl + D
Once the test fails, the statement following while will be executed.std::cout<<"Sum is:"<<sum<<std::endl;
This statement outputs sum followed by endl, where endl outputs a newline and flushes the buffer associated with cout.
Finally, return 0; is executed, usually indicating that the program has successfully finished running.
Introduction to Classes
In C++, we can define our own
data structuresby defining aclass.
Theclass mechanismis one of the most important features in C++.
C++’s main focus is that the behavior of the definedclass types(class type) can be as natural as built-in types.
In general, class types are stored in a file, and the file name usually matches the class name defined in the header file.Class types can be like built-in types, enabling you to define class type variables.
Example: sales_item item; indicates that item is an object of type sales_item.
It can be referred to as “a sales_item object” or “a sales_item”.
In addition to defining class type variables, the following operations can be performed on class objects:
- Use the
addition operator,+, to add two class objects.- Use the
input operator,>>, to read a class object.- Use the
output operator,<<, to output a class object.- Use the
assignment operator,=, to assign one class object to another.
Note: When involving operations with more than two class objects, these twoclass objectsshould be of the sameclass type.
When including custom header files in a program, use double quotes (“”) to include them.
Example: #include "sales_item.h"Note: Standard library header files use angle brackets <> while non-standard library header files use double quotes “”.
A Glimpse into Member Functions
What are member functions?
Member functions are functions defined by a class, sometimes referred to as class methods.
Member functions are defined once but are treated as members of each object.
They are called member functions because they (typically) operate on a specific object. In other words, they are members of that object, even if all objects of the same type share the same definition.
When calling a member function, the object on which the function is to operate is typically specified. The syntax uses the dot operator (
.):
Example:item.sales_isbn
Thedot operatorretrieves theright operandthrough itsleft operand.
Thedot operatoronly applies toclass type objects: theleft operandmust be aclass type object, and theright operandmust specify amember of that type.
Theright operandof thedot operator (.)is not an object or value, but thename of the member.
Executing a member function is similar to executing other functions: to call a function, thecall operator (())is placed after the function name.Call operatoris a pair of parentheses, enclosing theargument list(which may be empty) passed to the function.
C++ Variables and Basic Types
Programming languages share certain common features:
Built-in data types, such as integers and characters.Expression statements: Expression statements are used to manipulate values of the aforementioned types.Variables: Programmers can name the objects that variables operate on.Control structures: Such as if or while, allowing programmers to conditionally execute or repeatedly execute a set of actions.Functions: Programmers can use functions to abstract actions into callable computational units.C++ is a
statically typedlanguage, type checks are performed at compile time. The result is that before using a name in the program, the compiler must be informed of the type of that name.
One of the most important features in C++ isclasses, programmers can use classes to define custom data types. These types are sometimes referred to as “class types“ to distinguish them from the language’s built-in types.
One of C++’s primary design goals is to allow programmers to define types that are as easy to use as built-in types.
C++ defines several
basic types:character types,integer types,floating types, etc. C++ also provides mechanisms fordefining custom data types, with thestandard libraryleveraging these mechanisms to define many more complex types like variable-length stringsstring,vector, etc. Existing types can also be modified to form compound types.
Basic Built-in Types
C++ defines a set of arithmetic types representing integers, floating-point numbers, single characters, and boolean values. It also defines a special type called void.Void type: The void type has no corresponding value and is only used in limited scenarios, generally serving as the return type for functions with no return value.
The storage size of arithmetic types depends on the machine. Here, size refers to the number of binary bits (bit) used to represent that type.
C++ specifies the minimum storage space for each arithmetic type but does not prevent the compiler from using larger storage sizes. In fact, for the int type, nearly all compilers use storage space larger than required. (See table)
| C++ Arithmetic Types | ||
|---|---|---|
| Type | Meaning | Minimum Storage Space |
| bool | Boolean Type | - |
| char | Character Type | 8 bits |
| wchar_t | Wide Character Type | 16 bits |
| short | Short Integer | 16 bits |
| int | Integer | 16 bits |
| long | Long Integer | 32 bits |
| float | Single Precision Floating Point | 6 Significant Digits |
| double | Double Precision Floating Point | 10 Significant Digits |
| long double | Extended Precision Floating Point | 10 Significant Digits |
| Test Code: |
1 |
|
Output:
(Test platform is Windows 7 x64)
bool=1 byte
char=1 byte
wchar_t=2 byte
short=2 byte
int=4 byte
long=4 byte
float=4 byte
double=8 byte
long double=16 byte
Integer Types
Integer types: Represent arithmetic types for numbers, characters, and boolean values.Character types: There are two: char and wchar_t.
The char type ensures there is enough space to store any character corresponding to the machine’s basic character set value. Therefore, the char type is typically a single machine byte (byte).
The wchar_t type is used for extended character sets, such as Chinese and Japanese, where some characters cannot be represented by a single char character.
The short, int, and long types all represent integer values, with different storage space sizes. (The storage space size can vary depending on the platform and architecture) char < short <= int <= long (greater than or equal depending on the compiler).
The bool type represents the truth values true and false. Any value of arithmetic type can be assigned to a bool object. A value of 0 in arithmetic type represents false. Any non-zero value represents true.
Signed and Unsigned Integers
With the exception of the bool type, integer types can be signed or unsigned.Signed types can represent both positive and negative numbers (including 0), while unsigned types can only represent values greater than or equal to 0.
Important:
The range of
unsignedof the same type is usually twice that ofsigned(becausesignedhas one bit for the sign).
Important:
Integer typesint,short, andlongdefault tosigned. To obtain unsigned types, one must specify the type as unsigned.unsigned intcan be abbreviated asunsigned; appending no other specifier tounsignedmeans it is ofunsigned inttype.
There are three different types for char: char, unsigned char, and signed char. Although char has three different types, there are only two representation styles. You can use unsigned char or signed char to represent the char type.
unsigned char: 1255;127;signed char: -127
Whether the unmodified char is represented as signed or unsigned is determined by the compiler.
Representation of Integer Values
In unsigned types, all bits represent values.
The C++ standard does not define how
signed typesuse bits for representation; it is left to eachcompiler to decide freelyhow to represent signed types, and these representations will affect the value range of signed types.
For example, the value range of an 8-bit signed type is certainly from -127 to 127, but many implementations allow it to go from -128 to 127.
The most common strategy for representing signed integer types is to use one bit as the sign bit. If the sign bit is 1, the value is negative; if the sign bit is 0, the value is either 0 or positive.
A common strategy for an 8-bit signed integer results in a range of -127 to 127.
Integer Assignment
For unsigned types, the compiler is required to adjust out-of-range values to meet the requirements. The compiler will take that value modulo the number of possible values for the unsigned type. The resultant value will be taken.
For example, for an 8-bit unsigned char, which has a range of 0~255 (inclusive of 255), if a value exceeding this range is assigned, the compiler will take the value modulo 256.Modulo operation: “%”, remainder.
Note:
For unsigned types, negative numbers always exceed their value range. Unsigned objects can never hold negative numbers. In some languages, assigning a negative number to an unsigned object is illegal, but in C++, this is legal.
In C++, assigningnegative valuesto unsigned objects isperfectly legal, and the result is thenegative valuemodulo thenumber of possible valuesfor that type.
Example: Assigning -1 to an 8-bit unsigned char results in 255, as 255 is the remainder of -1 modulo 256.
When assigning a value beyond its range to a signed type, the actual assigned value is determined by the compiler. In practice, many compilers handle signed types similarly to unsigned types. That is, during assignment, the value is based on its number of possible values modulo. Note: However, we cannot guarantee that compilers will always handle signed types in this manner.
Floating-point Types
The types float, double, and long double represent single precision floating-point, double precision floating-point, and extended precision floating-point, respectively.
Generally, float uses 4 bytes (32 bits) to represent, double uses 8 bytes (64 bits), and long double uses 12 or 16 bytes (96 or 128 bits).
Note: The range of values for a type determines the number of significant digits contained in a floating point.
Typically, the precision of float types is insufficient — float types can only guarantee 6 significant digits. The double type can guarantee at least 10 significant digits, meeting the needs of most calculations.
Recommendation: Use built-in arithmetic types
- When performing arithmetic operations with integer types,
short typeis rarely used.- Using short type may lead to subtle assignment overflow errors.
- A typical case of assignment overflow (wrap around) occurs when the value is truncated to become a large negative number due to overflow.
- Although char type is an integer type, char type is typically used to store characters, not for calculations.
In some implementations, char type is treated as signed integer, while in others, it is treated as unsigned type; hence, using char type as a calculation type can lead to issues.
- In actual applications, most general-purpose machines use the same 32 bits to represent int types as they do for long types.
- When it comes to integer operations, machines that signify int types with
32 bitsandlong typeswith64 bitsface a dilemma in choosing betweeninttype orlongtype. On these machines, the runtime cost of performing calculations using long types vastly outweighs that of performing the same calculations using int types.- Floating point types: Using double types is unlikely to go wrong.
In float types,
implicit precision losscannot be ignored, while the cost of double precision calculations can be overlooked compared to single precision. In fact, on some machines, double computation can be significantly faster than float computation.
The precision provided by long double types is usually unnecessary and comes with extra runtime costs.
Literal Constants
Values like 42 are treated as literal constants, they are called literals because they can only be referred to by their value, and they are called constants because their values cannot be modified. Each literal has a corresponding type.
Note: Only built-in types have literal types; there are no literal types for class types. Thus, there are no literals for any standard library types.
Rules for Integer Literals
Defining literal integer constants can be done using any of the following three bases: decimal, octal, and hexadecimal.
- Octal: A literal integer constant that starts with 0 represents octal. For example: 024.
- Hexadecimal: Starts with 0x or 0X to represent hexadecimal. For example: 0x14.
The type of literal integer constantsdefaults tointorlong. The precise type depends on the literal — if it fitsint, it isint, if it exceedsint, it islong.
You can force a literal integer constant to convert to long, unsigned or unsigned long types by adding suffixes. By adding L or l (uppercase or lowercase “L”) to the number specifies it as long type.Note: When defining long integers, upper-case “L” should be used. Lower-case “l” can easily be confused with the number 1.
Similarly, you can specify unsigned types by adding U or u. Using both L and U will yield an unsigned long type literal constant.
128u
/*unsigned*/1024UL/*unsigned long*/
1L/*long*/8Lu/*unsigned long*/
Note: There is no literal type for short.
Rules for Floating-point Literals
Floating-point literal constants can be represented using decimal or scientific notation. When using scientific notation, the exponent is represented with E or e.
The default floating-point literal constant is of type double. Adding f or F after the number indicates single precision, while adding L or l indicates extended precision.
Boolean and Character Literals
Boolean literals: The words true and false are boolean type literals: bool test=true;.
Printable character literals are usually defined with a pair of single quotes: ‘a’, ‘b’, ‘c’.
Escape Sequences for Non-printable Characters
Non-printable and special characters are written using escape characters. Escape characters start with a backslash ().
C++ defines the following escape characters:
| Function | Escape Character | Function | Escape Character |
|---|---|---|---|
| Newline | \n | Horizontal Tab | \t |
| Carriage Return | \r | Vertical Tab | \v |
| Backspace | \b | Form Feed | \f |
| Backslash | \ | Single Quote | ' |
| Question Mark | ? | Double Quote | " |
| Alarm (bell) | \a | General Escape Character | \ooo |
General escape character: “\ooo”, where ooo represents three octal digits that denote the numeric value of the character.
Using the ASCII character set to represent literal constants:
\7(bell character)\12(newline character)\40(space character)\0(null character)\062(‘2’)\115(')
String Literals
String literals are a sequence of constant characters.
String literals are represented by zero or more characters enclosed in double quotes. Non-printable characters are represented as the respective escape characters.
Note: For compatibility with C language, all string literals in C++ are automatically appended with a null character at the end by the compiler.
The character literal
'A'represents a single character;
however,"A"represents the string containing the letter A and the null character.
Wide character literal: L'a'.
There are also wide string literals, similarly prefixed with “L”: L"a wide string literal" (\0).
Wide string literals are a sequence of constant wide characters, similarly ending with a wide null character.
Variables
Key concept:
Strong Static Typing
C++ is astatically typed language, performing type checks at compile time.The type of an objectrestricts the operations that can be performed on that object. If a type does not support a particular operation, then an object of that type will also not be able to perform that operation. (Example: a%b, both a and b are integers).
In C++, the legality of operations is checked atcompile time. When writing expressions, the compiler checks whether the objects in the expression are being used according to the usage defined by their types.
Static type checking helps us identify errors earlier. Static type checking means the compiler must recognize every entity in the program. Therefore, variables must be defined with their types before they can be used in the program.
What is a Variable?
A variable provides a named storage area for the program to operate on.
In C++, each variable has a specific type. This type determines the memory size and layout of the variable, the range of values that can be stored in that memory, and the set of operations that can be applied to that variable.
C++ programmers often refer to variables as “variables” or “objects”.
Lvalues and Rvalues
(1) Lvalue (lvalue, pronounced ell-value): Lvalues can appear on the left or right side of an assignment statement. (variables)
(2) Rvalue (rvalue, pronounced are-value): Rvalues can only appear on the right side of an assignment, cannot appear on the left side of an assignment statement. (constants)
1 | //units_sold, sales_price, total_revenue are variables (lvalues), they can be on the left side of an assignment statement. |
Note: Some operators, such as assignment, require that one of the operands must be an lvalue. As a result, the contexts in which lvalues can be used are more extensive than those for rvalues. The context in which an lvalue appears determines how the lvalue is used.
For example, in the expression:
In this expression, the variable
units_soldis used as an operand of two different operators.
The+ operatoronly cares about the values of its operands. The value of a variable is the current value stored in the memory associated with that variable. The addition operator takes the value of the variable and adds 1.
The variableunits_soldis also used as the left operand of the = operator.
The=operator takes the right operand and writes it to the left operand. In this expression, the result of the addition is stored in the storage unit associated withunits_sold, replacing its previous value.
Terminology: What is an Object?
An object is a region of memory that has a type. We can freely use objects to describe most of the data that can be manipulated in the program, regardless of whether these data are built-in types or class types, named or unnamed, readable or writable.
Variable Naming
Variable names, i.e., the identifiers for variables, can consist of letters, digits, and underscores.
Variable names must start with a letter or an underscore, and they are case-sensitive: identifiers in C++ are case-sensitive.
The language itself does not limit the length of variable names, but considering the readability and maintainability for others who may read or modify our code, variable names should not be excessively long.
C++ Keywords
C++ reserves a set of words as keywords in the language. Keywords cannot be used as identifiers in programs.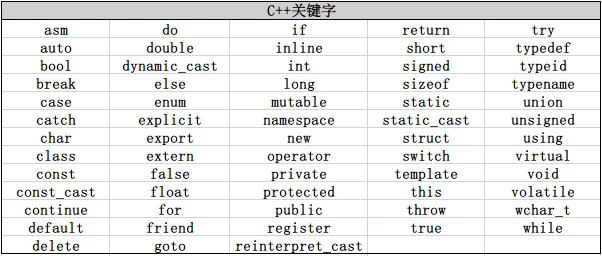
C++ also reserves certain terms as substitutes for operators. These alternatives support character sets that do not support the standard C++ operator symbol set. They also cannot be used as identifiers.
Note: Aside from keywords, C++ also reserves a set of identifiers for the standard library. Identifiers cannot contain two consecutive underscores and cannot begin with an underscore followed by an uppercase letter. Some identifiers (those defined outside functions) cannot start with an underscore.
Variable Naming Conventions
- Variable names generally use lowercase letters. For example: it is better to write index rather than Index or INDEX.
- Identifiers should use names that help with memory; that is, names that hint at their use in the program, such as on_loan or salary.
- Identifiers containing multiple words should be written with underscores between each word or capitalize the first letter of each embedded word. For example: it is better to write student_loan or studentLoan, rather than studentloan.
- The most important aspect of naming conventions is consistency.
Defining Objects
Every definition begins with a type specifier, immediately followed by a comma-separated list of one or more specifiers. The definition ends with a semicolon. The type specifier specifies the type associated with the object.
The type determines the storage space allocated to the variable and the operations applicable to it.
Multiple variables can be defined in the same statement:
1 | double salary,wage; |
Initialization
A variable definition specifies the variable’s type and identifier; it can also provide an initial value for the object. An object defined with an initial value is referred to as initialized (initialized).
C++ supports two forms of variable initialization:
- Copy initialization: The syntax of copy initialization uses the equals sign (=).
int ival = 1024;- Direct initialization: In direct initialization, the initialization expression is put within parentheses.
int ival(1024);
Note: In C++, understanding that “initialization is not assignment“ is essential; initialization and assignment are two different operations.
The difference between initialization and assignment: Initialization refers to creating a variable and assigning it an initial value, while assignment refers to overwriting the current value of an object with a new value.
When initializing class type objects, the difference between copy initialization and direct initialization is subtle and will be explained in detail in the subsequent chapter on copy control. Direct initialization syntax is more flexible and efficient.
Using Multiple Initialization Expressions
Initialization of built-in types has a single method: provide a value, with this value copied to the newly defined object. For built-in types, there is little practical difference between copy initialization and direct initialization.
With class type objects, some initializations can only be carried out via direct initialization.
Every class will define one or more special member functions to specify how to initialize class type variables. The member functions that define how to proceed with initialization are known as constructors. Like other functions, constructors can take multiple parameters. A class can define several constructors, each of which must accept different numbers or types of parameters.
As an example, the string class. String types are defined in the standard library for storing strings of varying lengths. To use string, the string header file must be included. Just like IO types, strings are defined within namespaces.string defines several constructors enabling us to initialize string objects in different ways. One way to initialize a string object is as a copy of a string literal:
1 | std::string titleA="C++ Primer"; |
Both of the above initialization ways can be used. Both definitions create a string object, initialized with the specified string literal copy.
You can also initialize a string object with a counter and a character. The created object contains a specified character repeated as many times as the counter specifies:
1 | //all_nines="9999999999" |
We will detail the string object in the section on sequential containers.
Initializing Multiple Variables
When two or more variables are defined in one definition, each variable may have its initialization expression. The names of the objects immediately become visible, so the value of the previously defined variable initializes the subsequent variable.
1 | //Direct initialization, wage is initialized to 10000 |
Initialized and uninitialized variables can be defined in the same definition. The two forms of syntax can be mixed.
1 | int interval,month = 11,day = 11,year = 1994; |
Objects can also be initialized with any complexity of expressions (including function return values):
1 | double price = 109.99,discount = 0.16; |
In the above example, the function apply_discount accepts two double values and returns a double value. The variables price and discount are passed to the function, with the return value used to initialize sale_price.
Rules for Variable Initialization
When defining variables that are not initialized, the system sometimes helps us initialize variables. What values the system provides depends on the type of the variable and where the variable is defined.
Initialization of Built-in Type Variables
Whether built-in variables are automatically initialized depends on where they are defined.
- Variables defined outside of functions are initialized to 0.
- Built-in type variables defined within the body of a function are not automatically initialized.
- Apart from being used as the left operand of an assignment operator, using uninitialized variables for any other purpose is undefined.
Note: Errors caused by uninitialized variables are difficult to detect. Never rely on undefined behavior.
It is suggested to initialize every built-in type object. Although this is not always necessary, it makes it easier and safer, unless you can confirm that ignoring initialization poses no risks.
Initialization of Class Type Variables
A class controls the initialization of class objects by defining one or more constructors.
Default constructor
If a variable of a certain class is defined without providing an initialization expression, that class can also define operations at the time of initialization. This is achieved by defining a special constructor known as the default constructor. This constructor is called “default constructor” because it runs by default.
If no initialization expression is provided, the default constructor will be used. This constructor will be executed regardless of where the variable is defined.
Most classes provide a default constructor. If a class has a default constructor, then when defining a variable of that class type, we can do so without explicitly initializing the variable.
For example, the
stringclass defines a default constructor that initializes string variables to empty strings, i.e., strings with no characters.
2
>std::string empty;
Declaration and Definition
C++ programs typically consist of many files. To allow multiple files access to the same variable, C++ distinguishes between declarations and definitions.
Declaration: A declaration has the extern keyword and lacks an initialization.
Variable definition (definition): Used to allocate memory for the variable and may also specify initial values for that variable. A variable has only one definition in a program.
Declaration (declaration): Informs the program of the variable’s type and name.
Definitions are also declarations: When a variable is defined, we declare its type and name. A variable can be declared multiple times, but can only be defined once.
Only when the declaration is also the definition can it include an initialization expression, as only definitions allocate storage space.
Initialization expressions must have storage space to perform initialization. If a declaration includes an initialization expression, then it can be treated as a definition, even if marked as extern:
1 | //Declaration without definition of i |
The extern declaration does not define anything or allocate storage space. In fact, it just states that the variable is defined elsewhere. A variable in a program can be declared multiple times, but can only be defined once.
Only when a declaration is also a definition can the declaration have an initialization expression since only definitions allocate storage space.
The initialization expression must have storage space to perform initialization. If the declaration includes an initialization expression, it can be treated as a definition, even if marked as extern:
1 | //Definition |
Only when the extern declaration is located outside of a function can it include an initialization expression. (Including the main() function)
Since initialized extern declarations are treated as definitions, subsequent definitions for that variable would be erroneous.
1 | //Definition |
Similarly, subsequent extern declarations that include initialization expressions would also be erroneous.
1 | //Definition |
The difference between declarations and definitions may seem trivial, but it is crucial.
Any variable used across multiple files needs a declaration that is separate from its definition. In such scenarios, one file includes the variable’s definition, while the files using that variable include its declaration (not its definition).
Scope of Names
C++ programs associate each name with a unique entity (e.g., variables, functions, and types).
The context distinguishing names of different meanings is termed scope. The scope is a region of the program. A name can be associated with a different entity in different scopes.
In C++, most scopes are defined with curly braces. Generally, names are visible from the point of declaration until the end of the scope where they are declared.
1 |
|
- Global scope (global scope): Defined outside all functions. (Ten)
- Local scope (local scope): Defined within a function. (sum)
- Statement scope (statement scope): Defined within a certain statement/block. (val)
C++ Scopes Can be Nested
Names defined in the global scope can be used within local scopes. Names defined in the global scope can also be used inside statement scopes defined within functions.
1 | //The global scope variable Ten and the local scope variable sum can both be used within statement scope |
When a global variable and a local variable have the same name, the local variable shadows the global variable.
1 |
|
Execution result: 0-1-2-3-4-5-6-7-8-9-10-100.
This demonstrates that the local variable index was not utilized within the for loop and was shadowed by the statement scope variable index.
In the statements chapter, we will discuss statement scope in detail, and in the functions chapter, we will discuss local and global scopes.
C++ also has two other distinct levels of scopes:
- Class scope: Introduced in the Classes and Data Abstraction section in the Classes chapter.
- Namespace scope: Covered in the Advanced Topics in the Namespace chapter.
Defining Variables Where They Are Used
Variable definitions or declarations can be placed anywhere within a program where statements can be placed. Variables must be declared or defined before they can be used.
Generally, defining an object at the place where it is first used is a good practice.
Defining an object where it is used for the first time can increase code readability. The reader does not need to return to the beginning of a code segment to locate a specific variable definition, and it is easier to assign a meaningful initial value to the variable when defined at that point.
One restriction on placing declarations is that a variable can only be accessed from where it is defined until the end of the scope that includes that declaration. The variable must be defined within the outer scope in which it is used.
const Qualifier
1 | for(int index = 0; index != 512; ++index){ |
The code above has two small issues:
- Readability of the program: What sense does it make to compare index and 512? What is the loop doing? What does 512 signify?
- Maintainability of the program: In very large programs, it is not safe or quick to modify the literal constant data.
The solution to these two problems is to use an object initialized to 512:
1 | int bufsize = 512; |
By using a memorable name to improve readability in the program.
Now it is tested against the object bufsize instead of the literal constant 512: index != bufsize;.
If you want to change the size of bufsize, you would not have to search and correct the instances of 512; you just need to modify the part of the initialization statement.
Defining Const Objects
A method to define a variable to represent a constant still has a serious issue: that is, the variable can be modified. The variable intended to represent constant values may be modified intentionally or unintentionally.
The const qualifier provides a solution that turns an object into a constant.
1 | const int bufsize = 512; |
This defines bufsize as a constant initialized to 512. The variable bufsize remains an lvalue, but now this lvalue cannot be modified. Any attempt to modify bufsize will result in a compile-time error.
1 | //Because constants cannot be modified after definition, it must be initialized during definition |
Const Objects Default to Local Variables
When defining non-const variables in the global scope, they are accessible throughout the entirety of the program.
Unless specified otherwise, const variables declared in the global scope are local to the file of that variable’s definition and cannot be accessed by other files.
By marking const variables as extern, they can be accessed throughout the entirety of the program.
1 | //file_1.cc |
Note: Non-const variables default to extern. To make const variables accessible in other files, they must be explicitly qualified as extern.
Quote
- Reference is another name for an object. In practical applications, references are mainly used as formal parameters for functions.
- A reference is a compound type, defined by adding the “&” symbol before the variable name.
- A compound type refers to a type defined by other types. In the case of references, each reference type is “associated with” some other type.
- Referencing type references cannot be defined, but any other type of reference can be.
1 | // References must be initialized with an object of the same type as the reference |
References as Aliases
Because a reference is just another name for the object it binds to, operations performed on the reference actually operate on the object that the reference binds to.
1 | // Operations on reference // Effect is equivalent to |
Similarly:
1 | // Assign the value associated with ival to variable ii |
Once a reference is initialized, this reference exists as long as it remains bound to the object it pointed to during initialization. It cannot be bound to another object. (Uniqueness)
Since operations on a reference directly affect the object associated with it, the reference must be initialized upon definition. The only way to indicate which object it points to during initialization.
Defining Multiple References
Multiple references can be defined in a type. The “&” symbol must be added before each reference identifier.
1 | int i = 1024, i2 = 2048; |
const References
Const references are references to const objects. The referenced object cannot be modified through the reference.
1 | const int ival = 1024; |
Note: Binding a regular reference to a const object is illegal.
Const references can be initialized to objects of different types or initialized to rvalues.
1 | // Such as literal constants |
However, the same initialization is illegal for non-const references and might lead to compilation errors.
1 | double ival = 3.14; |
At this point, you might wonder, isn’t it said that a reference is just another name for an object? Then why, after modifying the object’s value, does the corresponding reference’s value remain unchanged?
Here, one must first consider what happens when a reference is bound to a different type:
2
3
4
5
6
7
8
double dval = 3.14;
const int &refdval = dval;
// The compiler will convert this code into encoded form as follows
double dval = 3.14;
// Assigning a double variable to an int variable will cause a forced conversion (double -> int)
int temp = dval;
const int &refdval = temp;Because dval is not const, it can be assigned a new value. Doing so will not modify the variable temp used during forced conversion, hence will not change the value of the reference bound to temp.
- Non-const references can only bind to objects of the same type as the reference.
1 | int ival = 1024; |
- Const references can bind to different but related types or bind to rvalues. (Beware of the forced type conversion when const is bound to a different type that allows modifications to the referenced object but won’t affect the const reference)
1 | // Such as literal constants (rvalue) |
typedef Names
typedef can be used to define type names:
1 | typedef double wages; // wages is a synonym for double |
typedef names can be used as type specifiers:
1 | wages hourly, weekly; // double hourly, week; |
Typedef definitions start with the keyword typedef, followed by the data type and identifier. Identifiers or type names do not introduce new types but merely synonyms for existing data types.
Typedef names can appear in any position where type names are allowed in the program.
typedef is typically used for the following three purposes:
- To hide the implementation of a specific type and emphasize the purpose of using the type.
- To simplify complex type definitions, making them easier to understand.
- To allow one type to serve multiple purposes while making each usage’s intention clear.
Using typedef to Simplify Function Pointer Definitions
Function pointers can be quite verbose. Using typedef to define synonyms for pointer types can greatly simplify the use of function pointers.
1 | typedef bool (*cmpFcn)(const string &, const string &); |
This definition indicates that cmpFcn is a name for a pointer type that points to a function returning a bool type with two const string reference parameters. When using this function pointer type, simply use cmpFcn without having to write the entire type declaration each time.
Enum
We often need to define a set of selectable values for certain attributes. For example, there may be three statuses for a file open: input, output, and append. One way to record these statuses is to associate each with a unique constant.
1 | // We might write code like this |
Enumeration provides a way to define a set of integer constants and group them together.
Defining and Initializing an Enum
The definition of an enum includes the keyword enum, followed optionally by an enum type name, and a list of enumerators enclosed in braces and separated by commas.
1 | // input is 0, output is 1, append is 2 |
By default, the first enumerator is assigned the value 0, and each subsequent enumerator has a value one greater than the previous.
Enum Members are Constants
You can provide initial values for one or more enumerators, and the values used to initialize the enumerators must be constant expressions.
A constant expression is an expression that the compiler can compute during compilation.
Integer literal values are constant expressions, just like a const object self-initialized through a constant expression.
You can define the following enum types:
1 | // shape is 1, sphere is 2, cylinder is 3, polygon is 4 |
The enumerator values can be non-unique:
1 | // point2d is 2, point2w is 3, point3d is 3, point3w is 4 |
Note: You cannot modify the value of enum members. Enum members are constant expressions in themselves, so they can be used anywhere a constant expression is needed.
Each Enum Defines a Unique Type
Each enum defines a new type. Like other types, you can define and initialize objects of type Points (the enum type created in the example) and use these objects in different ways.
Initialization or assignment of enum type objects can only be done using their enumerators or other objects of the same enum type.
1 | // testA is 0, testB is 1, testC is 2 |
Class Types
In C++, a class is defined to create custom data types. The class defines the data contained in objects of that type and the operations that objects of that type can perform.
Designing Classes Starting with Operations
Each class defines an interface and an implementation.
The interface consists of the operations needed by the code that uses the class. The implementation generally includes the data needed by the class. The implementation also includes functions that are necessary for the class but are not intended for general use.
When defining a class, it is common to define its interface first, i.e., the operations the class provides. Through these operations, one can determine what data is needed for the class to fulfill its functionality and whether additional functions need to be defined to support its implementation.
For example, operations supported by the defined type:
- Addition operator to add two Sales_item objects
- Input and output operators to read and write Sales_item objects
- Assignment operator to assign one Sales_item object to another
- same_isbn function to check whether two objects refer to the same book
We will introduce how to define these operations in the Functions chapter and the Class and Data Abstraction section’s Operator Overloading and Conversion chapter. Consideration of the necessary functionalities allows us to ascertain the required data for the class.
Sales_item must include:
- Record the number of sales for a particular book
- Record the total sales for that book
- Compute the average selling price for that book
From the above tasks, we see that we need an unsigned type object to record the number of books sold, a double type object to record total sales revenue, and then we can calculate the average price by dividing total revenue by the number of books sold. Since we also need to know which book is being recorded, we need to define a string object to keep track of the book’s ISBN.
Defining Classes
We need to define a type consisting of the data elements we designed for the class and the data types of the operations used earlier. In C++, the method to define such a data type is to define a class.
1 | class Sales_item { |
Class definitions start with the keyword class, followed by the class identifier. The class body is contained within braces. There must be a semicolon following the braces.
Forgetting the semicolon after a class definition is a common programming error!!
The class body can be empty. The class defines the data and operations that comprise that type. These operations and data are part of the class and are also known as members of the class; operations are called member functions, and data are called data members.
Member functions: Member functions are functions defined by the class and are sometimes referred to as class methods.
Member functions are defined only once and are viewed as members of each object.
When calling a member function, the object the function is to operate on is specified (typically) through the dot operator (.).
The dot operator takes its left operand to obtain the right operand.
The dot operator is used only for class-type objects: the left operand must be a class-type object, and the right operand must specify a member of that type.
Note: The right operand of the dot operator (.) is not an object or value, but the name of the member.
Classes can also contain zero to many private or public access specifiers. Access specifiers control whether members of the class can be accessed from outside the class. Code that uses the class can only access public members.
Defining a class also means defining a new type. The class name is the name of that type.
Each class defines its own scope. That is, the names of data and operations within the class must be unique but can reuse names defined outside the class.
Defining Class Data Members
Defining class data members is somewhat similar to defining ordinary variables.
You simply specify a type and give the member a name:
1 | // When defining a Sales_item type object, these objects will contain a string variable, an unsigned variable, and a double variable |
Class data members define the content of that object.
There are very important differences between defining variables and defining data members:
- Generally, you cannot initialize class members as part of their definition.
- When defining data members, you can only specify the names and types of the data members.
- Classes do not initialize data members during their definition but control initialization through special member functions called constructors.
Access Specifiers
Access specifiers control whether code using the class can use a given member.
Member functions of the class can use any member of the class, regardless of the access level.
Access specifiers private and public can appear multiple times in a class definition. The given access specifier applies until another access specifier appears.
Members defined in the public section of the class can be accessed anywhere in the program. Typically, operations are placed in the public section so that any code in the program can execute these operations.
Code that is not part of the class cannot access private members. This ensures that code operating on class objects cannot directly manipulate their data members.
Using the struct Keyword
C++ supports the struct keyword, which can also define class types. The struct keyword is inherited from the C language.
If the class is defined using the class keyword, any member before the first access specifier is implicitly private; if the struct keyword is used, those members are public by default.
You can equivalently define the Sales_item class as:
1 | struct Sales_item { |
Struct members are public by default unless specified otherwise, so there’s no need to add the public label.
The only difference between defining a class with the class and struct keywords is the default access level.
By default, struct members are public, while class members are private.
Writing Your Own Header Files
Class definitions are generally placed in header files. C++ programs use header files to include not just class definitions.
Remember, names must be declared or defined before use. Programs made up of multiple files need a way to connect the usage and declarations of names. In C++, this is achieved through header files.
To allow programs to be divided into independent logical blocks, C++ supports what is known as separate compilation. This way, programs can consist of multiple files.
Designing Your Own Header Files
Header files provide a centralized location for related declarations. Header files typically contain class definitions, extern variable declarations, and function declarations.
Proper use of header files can bring two benefits:
- Ensure that all files use the same declaration for a given entity
- When declarations need modification, only the header file needs to be updated
When designing a header file, consider the following points:
- Declarations within a header file should logically belong together
- Compiling header files requires time
- If the header file is too large, programmers may be unwilling to incur the compilation cost of including that header file.
Header Files for Declarations, Not Definitions
When designing header files, it’s essential to remember the difference between definitions and declarations. Definitions can only appear once, while declarations can appear multiple times.
The following statements are definitions and should not be placed in header files:
1 | extern int ival = 100; // Even though there is an extern keyword, it has initialization, so this statement is a definition. |
Having two or more files in the same program containing any of the above definitions will result in multiple definition link errors.
Note: Because header files are included in multiple files, they should not contain definitions for variables or functions.
There are three exceptions to the rule against definitions in header files:
- Defining classes is allowed
- Const objects known at compile-time
- Inline functions (inline functions)
Some const Objects Defined in Header Files
Const variables default to being local variables of the file that defines them.
When a const integer variable is self-initialized through a constant expression, that const integer variable can become a constant expression. For a const variable to be a constant expression, its initializer must be visible to the compiler. To allow multiple files to use the same constant value, the const variable and its initializer must be visible to each file. To make the initializer visible, it is generally advisable to define such const constant expressions in header files. This way, regardless of when the const variable is used, the compiler can see its initializer.
C++ states that any variable can only be defined once. Definitions allocate memory space, and all uses of that variable are associated with the same storage space. Since a const object is assumed to be a local variable in the file that defines it, defining them in header files is legal.
This behavior has a significant implication:
When we define a const variable in a header file, each source file that includes that header file has its own const variable, all with the same name and value.
When that const variable is initialized with a constant expression, it can guarantee that all variables have the same value. However, in practice, most compilers will replace those uses of const variables with the corresponding constant expressions during compilation. Therefore, in practice, no storage space is allocated for storing const variables initialized with constant expressions.
If a const variable is not initialized with a constant expression, it should not be defined in a header file. Instead, like other variables, that const variable should be defined and initialized in a source file. An extern declaration should be added for it in the header file to allow sharing among multiple files.
A Brief Introduction to Preprocessors
#include is part of the C++ preprocessor.
The preprocessor processes the source code of a program and runs before compilation.
Include receives a single argument: the name of the header file. The preprocessor substitutes the content of the specified header file into each instance of #include.
Header Files Often Need Other Header Files
Header files frequently need to #include other header files. For instance, the header file for the Sales_item class must include the string library, as the Sales_item class contains a data member of type string and thus must have access to the string header file.
Including header files is quite common, and sometimes one header file is included multiple times. For example, a program using the Sales_item header file may also use the string library. In such cases, string might be included twice: once through direct inclusion in the program and once through indirect inclusion via the Sales_item header file.
It’s crucial to design header files so that they can be included multiple times in the same source file. We must ensure that including the same header file multiple times does not cause multiple definitions of classes and objects defined within that header file.
A common practice to secure header files against this is to use preprocessor-defined header guards, which prevent the contents of a header file from being processed again if it has already been seen.
Avoiding Multiple Inclusions
The preprocessor allows us to define variables.
Preprocessor variables must have unique names in the program. Any use of names matching a preprocessor variable is associated with that preprocessor variable.
To avoid name conflicts, preprocessor variables are often represented in all uppercase letters.
Preprocessor variables have two states: defined or undefined. Defining a preprocessor variable and checking its state uses different preprocessor directives.
#defineinstructs to take a name and define it as a preprocessor variable.#ifndefchecks if the specified preprocessor variable is undefined. If it is undefined, all directives following it are processed until#endifis encountered.
You can use these tools to prevent multiple inclusions of the same file:
1 |
Note: Header files should contain guards even if those header files are not included by others. Writing header guards is not complicated, and they can prevent hard-to-understand compilation errors in case a header file is included multiple times.
Using Your Own Header Files
The #include directive accepts two formats:
1 |
- If the header file is in angle brackets (<>), it’s treated as a standard header file. The compiler will search for it in a predefined set of locations (PATH).
- If the header file name is enclosed in quotes (“”), it is treated as a non-system header file, and the search for non-system header files typically begins with the directory where the source file is located.

