As the scale of projects increases, the number of Shader variants in UE gradually accumulates, often reaching millions of Shader variants. Although UE provides the Share Material Shader Code feature to avoid duplicate storage of Shaders by serializing them into a standalone ushaderbytecode file, it can still occupy hundreds of megabytes of package size. By default, UE places these NotUAsset files in Chunk0, which must go into the base package, significantly affecting the base package for mobile platforms where hundreds of megabytes could hold many resources.
To solve this issue, we can only tackle it from three aspects:
- Reduce the number of variants in the project, dump Shader information from the project, and analyze which ones are unnecessary;
- Split shaderbytecode so that the base package only contains essential Shaders, while others are downloaded as needed. However, UE does not provide such a mechanism by default, but you can use my developed HotPatcher to split the base package, generate multiple shader libs, and dynamically download resources and required shaderbytecode using the hot update process.
- Use a compression algorithm with a higher compression ratio to compress ShaderCode; the engine by default uses LZ4.
The first approach requires collaboration between TA and artists, making significant improvements relatively difficult. The second solution is detailed in previous articles about hot updates (Unreal Engine#热更新). This article starts from the third approach, implementing a special compression method for Shaders that effectively reduces the size of shaderbytecode, significantly improving the compression ratio of Shaders and can be combined with solution 2 to enhance compression while splitting shaderbytecode.
Forward
In Project Settings-Project-Packaging, enable Share Material Shader Code:
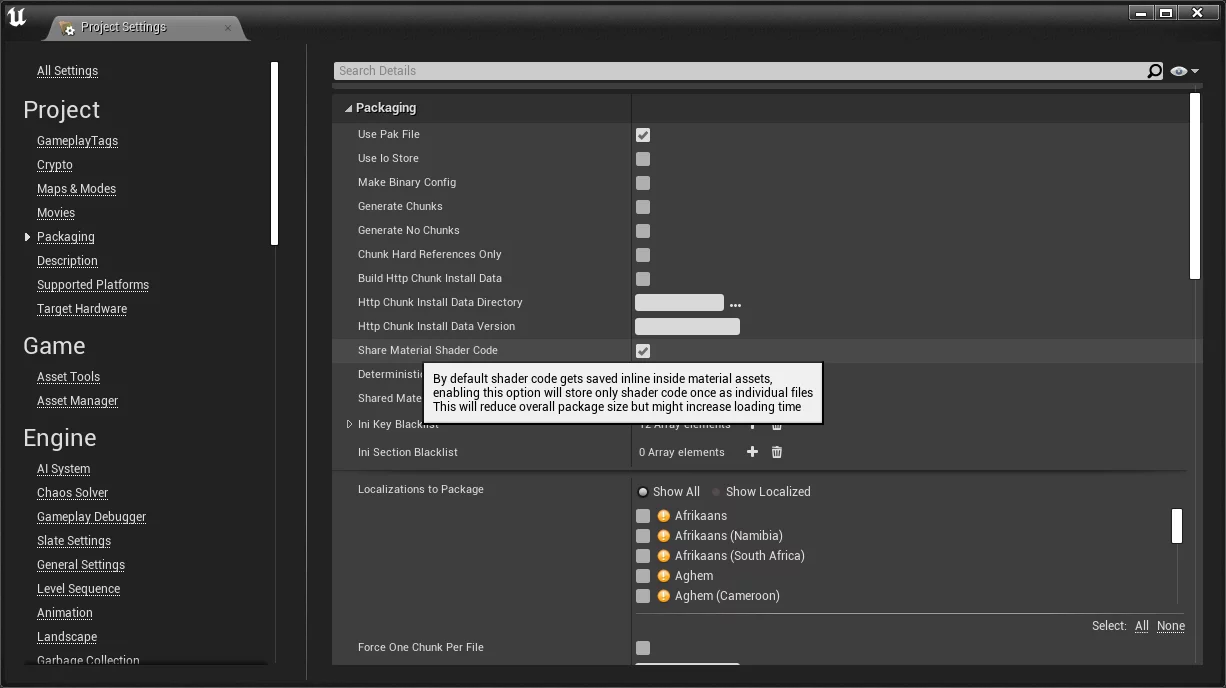
By default, after enabling this feature, UE will generate two shaderbytecode files in the Cooked ../../../PROJECT_NAME/Content (for iOS, compiled as Native, these are metalmap and metallib):
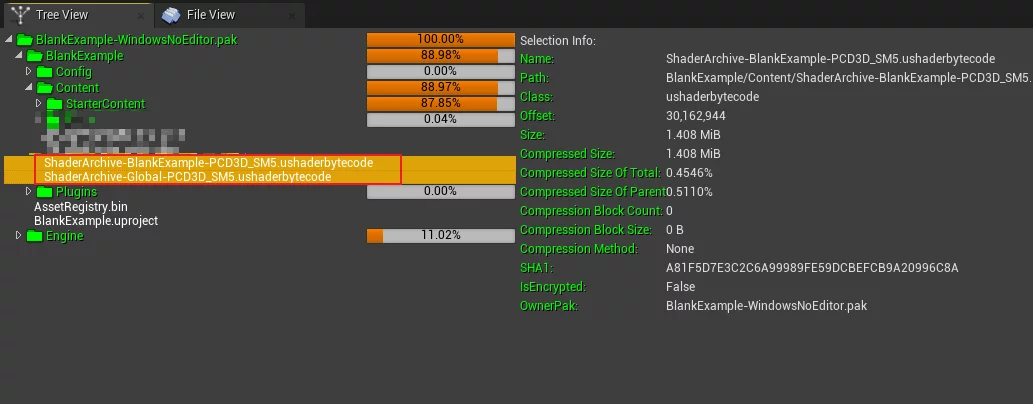
These two files store all Shaders in the project.
The engine also provides a default Shader compression mechanism using LZ4, which can be controlled via Console Variable:
1 | r.Shaders.SkipCompression=0 |
A non-zero value disables compression.
After compiling the Shaders, the compression process is executed when adding Shaders to ShaderMap:
1 | void FShaderMapResourceCode::AddShaderCode(EShaderFrequency InFrequency, const FSHAHash& InHash, TConstArrayView<uint8> InCode) |
However, even after using LZ4 for compression, the size of shaderbytecode remains very large (100K Shaders reaching 91M):
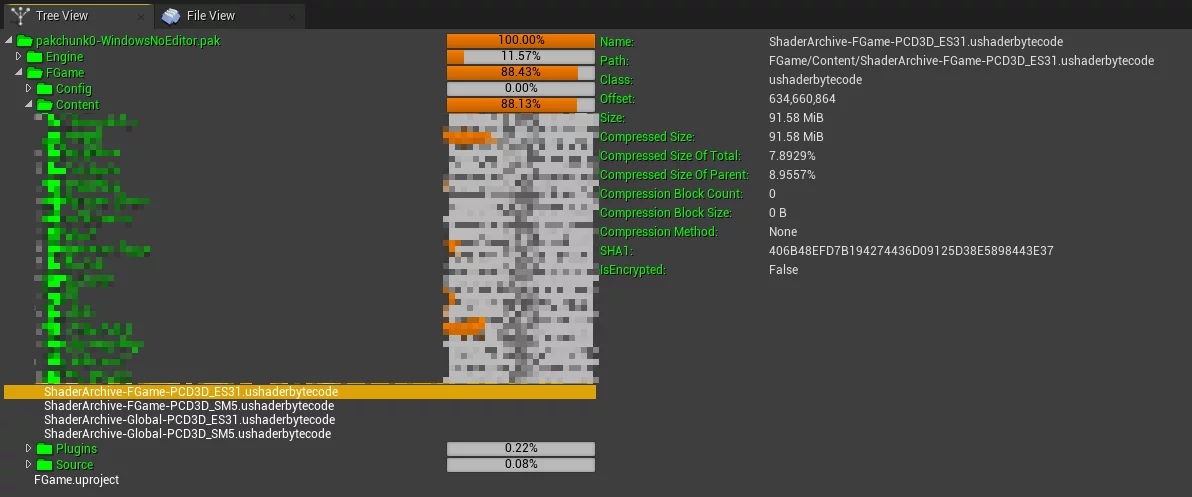
Moreover, if the target platform supports multiple Shader Formats, as depicted above supporting both SM5 and ES31, the size may double.
ZSTD
In previous blog posts, I introduced integrating ZSTD into UE as a PAK compression algorithm to improve Pak’s compression ratio:
- ModularFeature:Integrating ZSTD Compression Algorithm into UE4
- Performance Comparison of Compression Algorithms: Zlib/Oodle/ZSTD
In game projects, the performance of ZSTD is slightly weaker than RAD’s Oodle algorithm, which has been integrated into UE after Epic acquired it and is used as the default compression algorithm in 4.27+.
The size of each ShaderCode typically ranges from several kB to 100 kB. Generally, compressing such small data poses challenges, as compression algorithms rely on existing data to compress future data. Small files lack sufficient data sets to significantly improve compression ratios.
However, ZSTD offers a special compression mode: it trains a dictionary from existing data to compress small data effectively, making it very suitable for compressing Shader files.
The performance data provided by ZSTD is also excellent:
| Compression Ratio | Compression Speed | Decompression Speed |
|---|---|---|
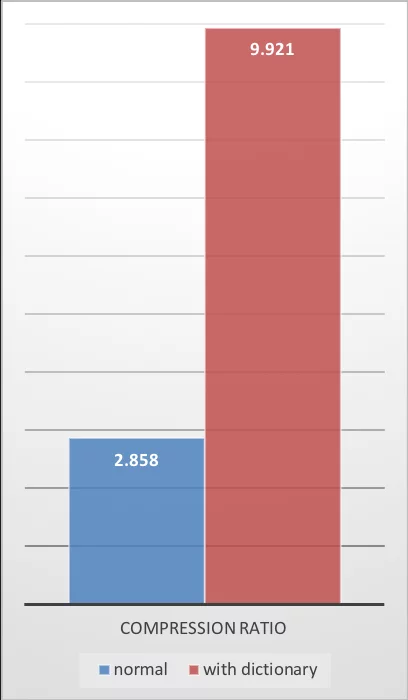 |
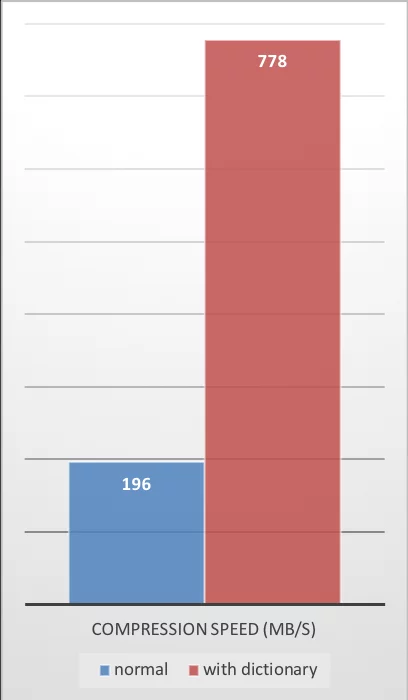 |
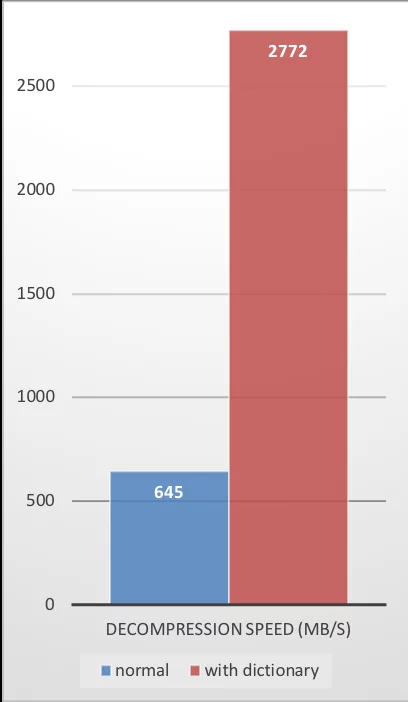 |
The creation of the training set and the commands for compression and decompression provided by ZSTD are:
1 | # Create dictionary |
You can use zstd --help to see more commands.
So, how can we integrate this approach into UE?
Integration into UE
First, as mentioned in the previous section, the dictionary-based compression method requires training a dictionary from existing data, which in UE needs to be based on uncompressed ShaderCode.
Update 20220718: I have provided an efficient dictionary training scheme that avoids modifying the engine and the need to cook again. For details, see the article: An Efficient ZSTD Shader Dictionary Training Solution
The integration process roughly requires the following steps:
Disable the default Shader compression in the engine.During the serialization process of Shaders, dump all ShaderCode.Use ZSTD based on the dumped Shader files as a training set to create a dictionary.Integrate ZSTD into UE to compress ShaderCode based on the dictionary.Serialize the compressed ShaderCode into ushaderbytecode.Simultaneously, modify the engine’s part that reads Shader from ushaderbytecode to ensure that ShaderCode can be correctly decompressed.
However, it is essential to note the following points:
When using ZSTD to create a dictionary from a training set, pay attention to:
- Ensure that the training set is sufficiently large; the size ratio of the training set to the dictionary should at least be 10-100 times. The larger the training set, the better the dictionary’s compression effect.
- The default maximum dictionary size for
zstdis110k. You can estimate the dictionary size based on the training set size using a factor of 100 and specify it with--maxdict. - Ensure that the dumped Shader data is uncompressed.
Currently, the specific implementation is not open-sourced; the above points are the core steps of the implementation, and the Shader loads correctly at runtime:
Compression Effect and Performance
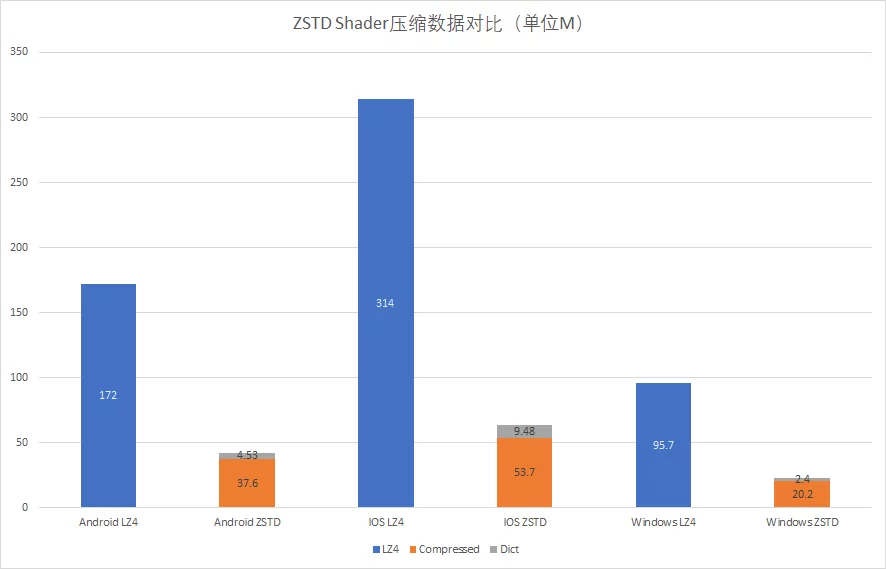
Different compression algorithms for Shader data:
| Android_ASTC | IOS | WindowsNoEditor | |
|---|---|---|---|
| LZ4 | 172 | 314 | 95.7 |
| ZSTD | 37.6 | 53.7 | 20.2 |
| Dict | 4.53 | 9.48 | 2.4 |
After optimization, using the ZSTD + dictionary approach for Shader compression achieves approximately 65%-80% compression ratio improvement compared to the engine’s default LZ4, yielding remarkable results.
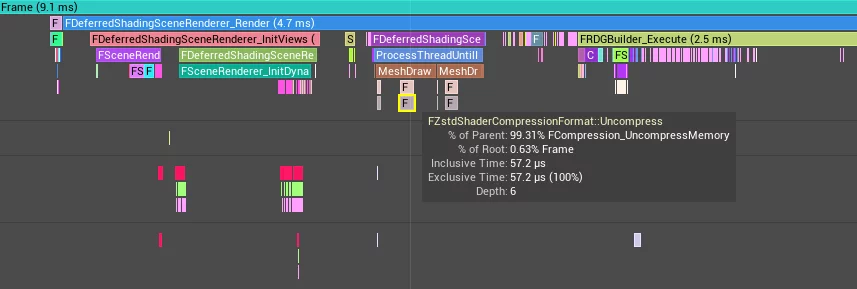
The decompression time at runtime:
Conclusion
Through testing, the method based on ZSTD + dictionary significantly improves the Shader compression ratio compared to LZ4, reducing the size of shaderbytecode within the package.
However, it still requires first Dump Shader to manually train the dictionary before proceeding with the compression process. The original packaging workflow in UE does not facilitate this process for automation. The future direction is to achieve automation for the entire packaging and optimization process, which can be smoothly integrated into Shader serialization through the framework of HotPatcher, allowing for seamless dictionary training and application during Shader compression, with subsequent integration planned for HotPatcher.

