In the article ZSTD Dictionary-based Shader Compression Scheme, I introduced a method for compressing UE’s ShaderCode using ZSTD dictionaries, which can significantly improve the compression ratio of ShaderLibrary. However, the process of training the dictionary and using it for compression remains complex and is not an efficient engineering implementation:
- The engine’s default Shader compression must be turned off.
- You need to cook the project once to dump the ShaderCode of each unique Shader.
- Based on the dumped ShaderCode files, use the ZSTD program to train the dictionary.
- Execute a full cook process again to compress using the dictionary and generate the final shaderbytecode.
According to the above process, changing the engine is necessary to dump ShaderCode; moreover, the disjointed workflow means that after dumping ShaderCode, you must invoke the zstd program to train the dictionary; finally, you still need to cook the project again to compress the Shader using the trained dictionary. Additionally, turning off Shader compression will cause DDC Cache Miss with LZ4 compression, leading to significant time overhead from repeated cooking, which is unacceptable in projects with a large number of Shaders.
Based on this pain point, I researched and implemented an efficient dictionary training method that requires no changes to the engine, allowing for rapid training of the dictionary and compression based on that dictionary. It can directly train the dictionary from ushaderbytecode and generate ushaderbytecode using ZSTD + dictionary compression, greatly improving processing efficiency. This is a completely Plugin-Only implementation, with almost zero integration cost, and will later be released as an extension module of HotPatcher.
Based on the aforementioned dictionary training process, the core issues are threefold:
- How to efficiently obtain uncompressed ShaderCode.
- How to eliminate dependence on the ZSTD program and implement dictionary training entirely within UE, avoiding additional IO processes.
- How to avoid re-cooking and only use the dictionary to compress ShaderCode.
The content of this article will systematically analyze and address these three issues.
DumpShaderCode
What is the most reasonable Dump method?
To efficiently dump ShaderCode, we need to clarify one question: where is the most reasonable place to dump?
- When the Shader compilation is complete.
![]()
- At
FShaderCodeLibrary::AddShaderCode(serializingushaderbytecode).![]()
The approach in ZSTD Dictionary-based Shader Compression Scheme suggests using FShaderCodeLibrary::AddShaderCode, because Shader cached from DDC will not go through the compilation process again. If done when the Shader compilation is complete, it will miss DDC cached shaders.
However, neither of these methods is the best solution. A careful consideration reveals that the final package already contains all the final ShaderCode for the current platform:
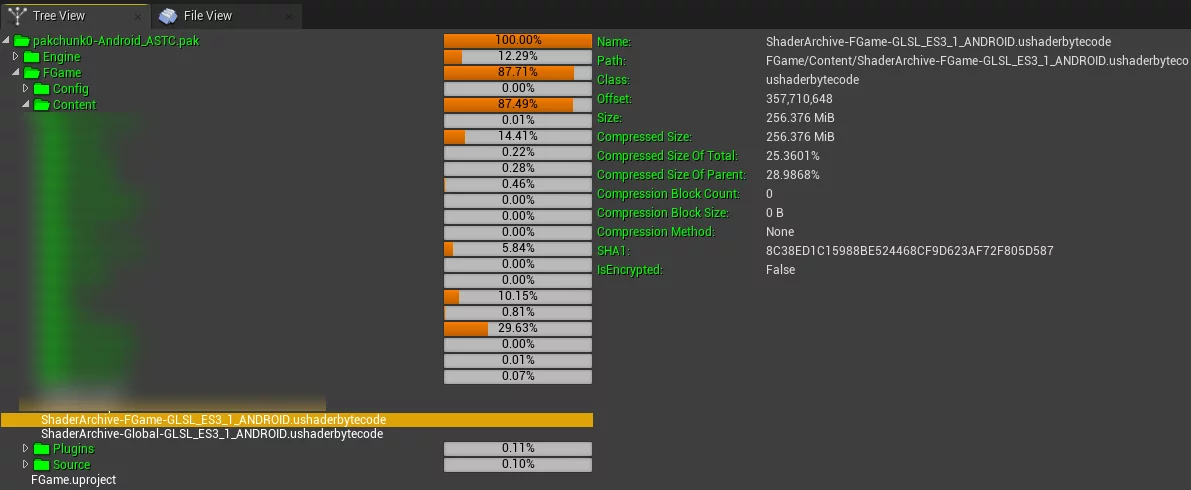
By default, the two ushaderbytecode files, Global and ProjectName in the project, constitute the complete ShaderLibrary of the project, which is by default compressed using LZ4.
If we can directly extract the original uncompressed ShaderCode from the default packaged ushaderbytecode for training, we can avoid the repeated cooking process.
To achieve this, we need to analyze the ushaderbytecode file format.
Analysis of ushaderbytecode format
The ushaderbytecode file is a container for managing ShaderCode in UE, used for storing the correspondence between shader hash and shader code for runtime querying and loading.
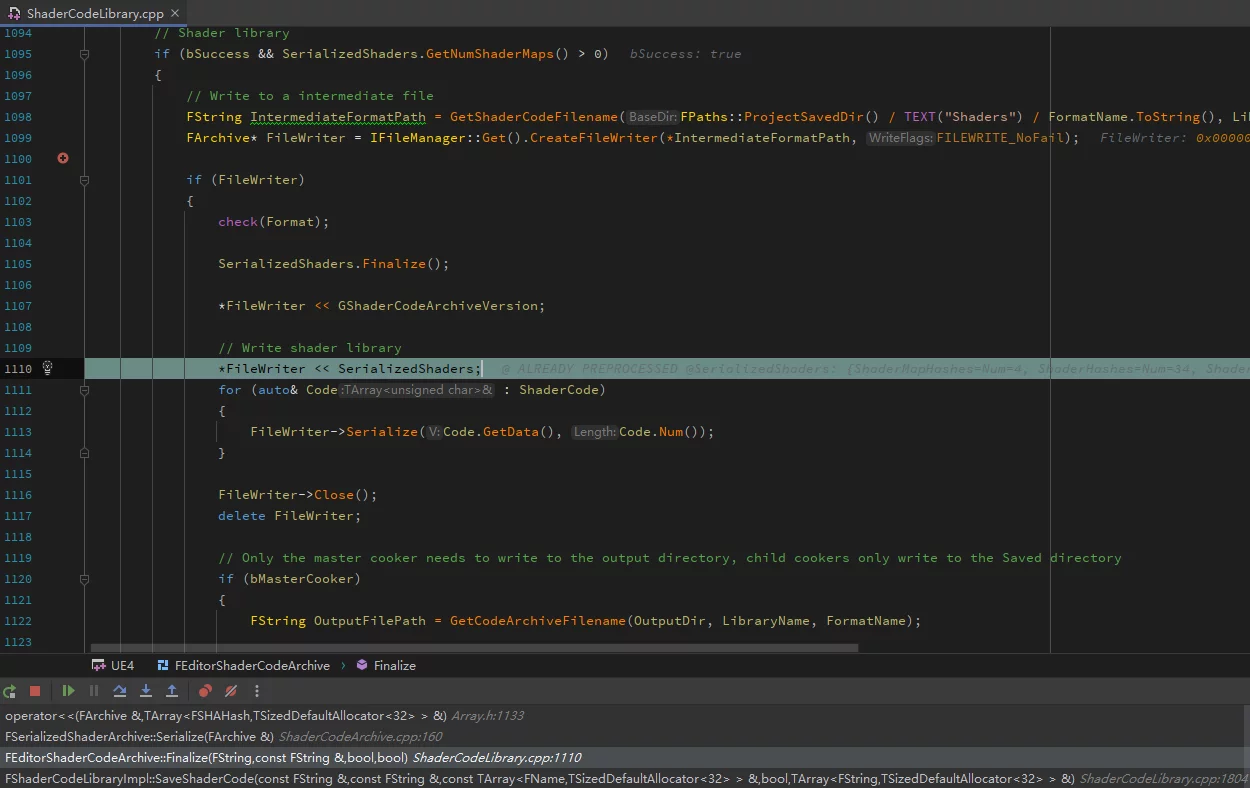
The serialization of the ushaderbytecode file is implemented in ShaderCodeLibrary within FEditorShaderCodeArchive::Finalize.
The final file format of ushaderbytecode:
unsigned int GShaderArchiveVersion=2;Four bytes, records the version number of ShaderArchive.FSerializedShaderArchive SerializedShaders;Records the hash, offset, and other information of shaders, serving as an index for ushaderbytecode, to document all shader information included in the current shaderbytecode and the offset of a particular ShaderCode in the file.
1 | class RENDERCORE_API FSerializedShaderArchive |

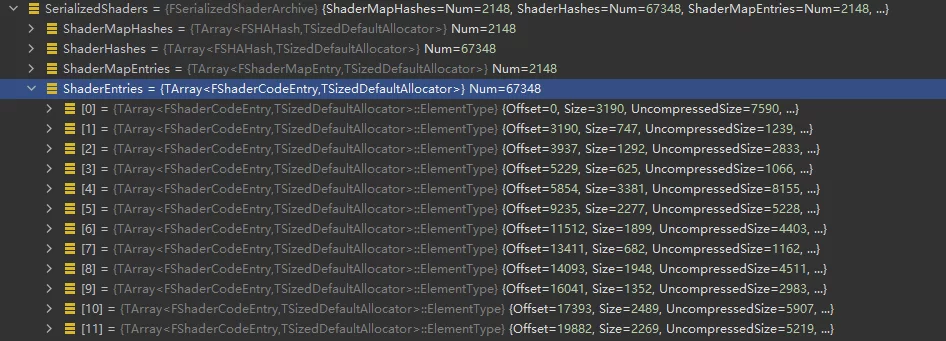
- ShaderCode array, containing all compiled ShaderCode serialized in order.
During runtime, when FShaderCodeLibrary loads a ushaderbytecode via OpenLibrary, it doesn’t fully load the file into memory. It only serializes GShaderArchiveVersion and the FSerializedShaderArchive structure:
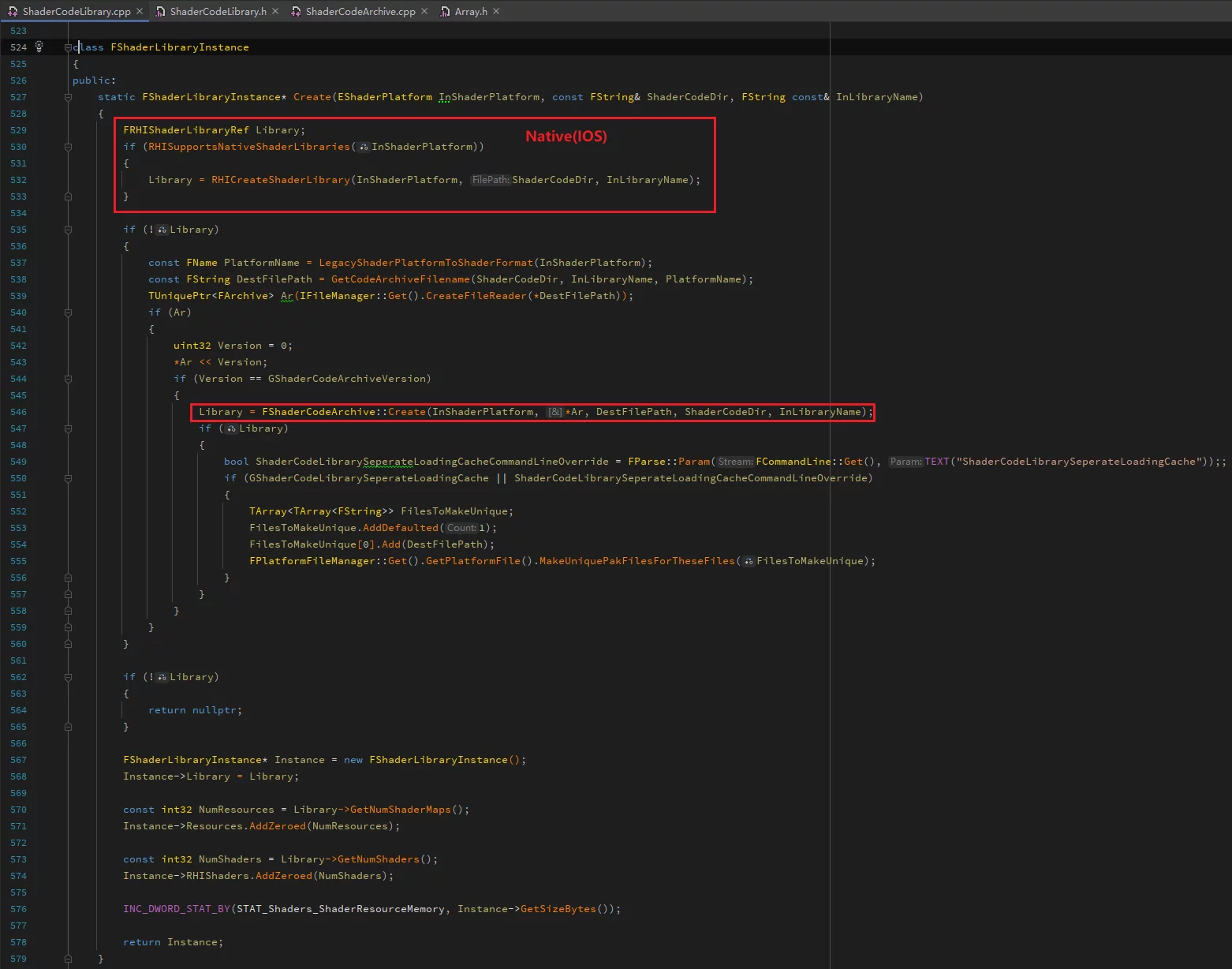
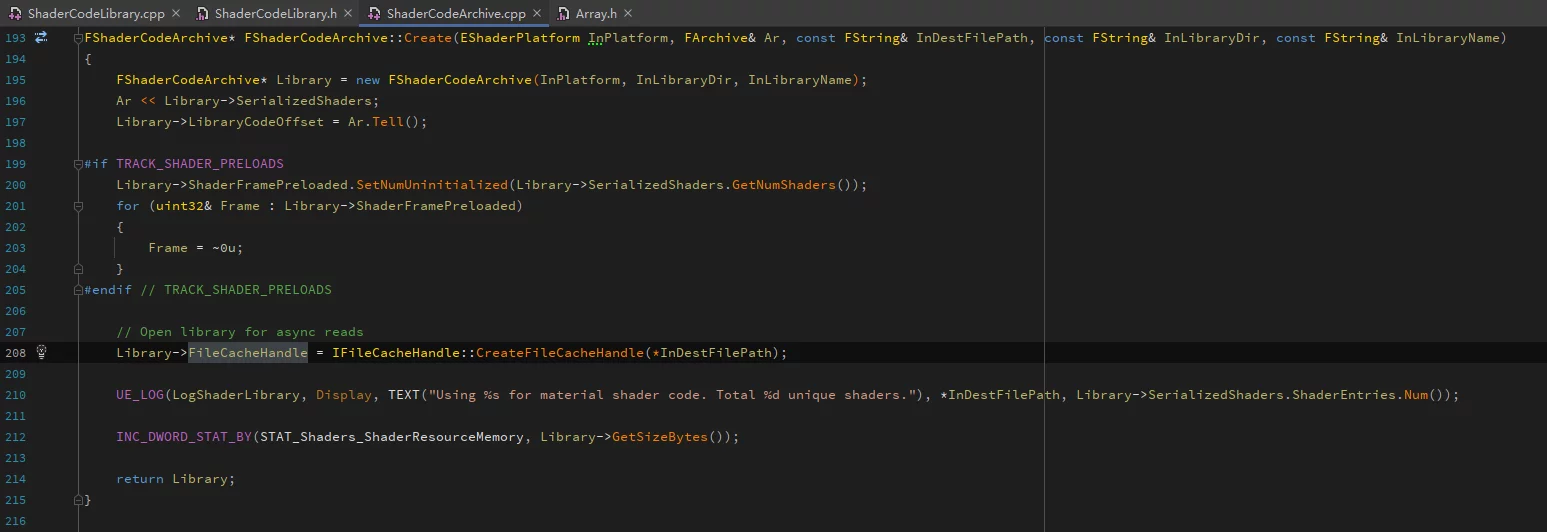
It retrieves the index structure, version number, and file handle (FileCacheHandle) for loading the true ShaderCode.
Necessary explanations of certain concepts:
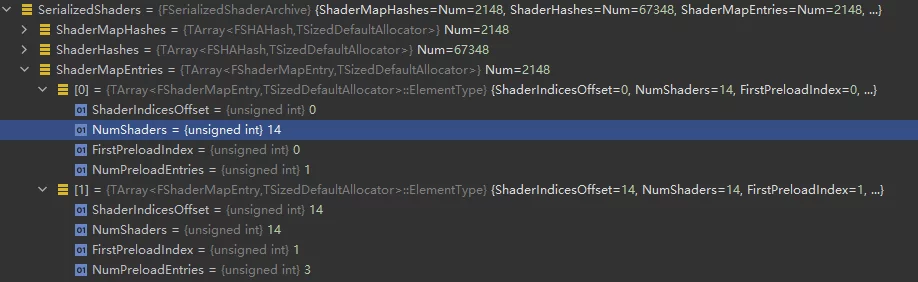
- ShaderMap contains multiple ShaderCodes; for instance, a Material can generate multiple Shader variants, which are all located within the same ShaderMap.
- ShaderCodes across multiple ShaderMaps can be reused and may have cross-referencing relationships; however, the ShaderCodes are not genuinely copied. The Shaders in ShaderMap are indexed by
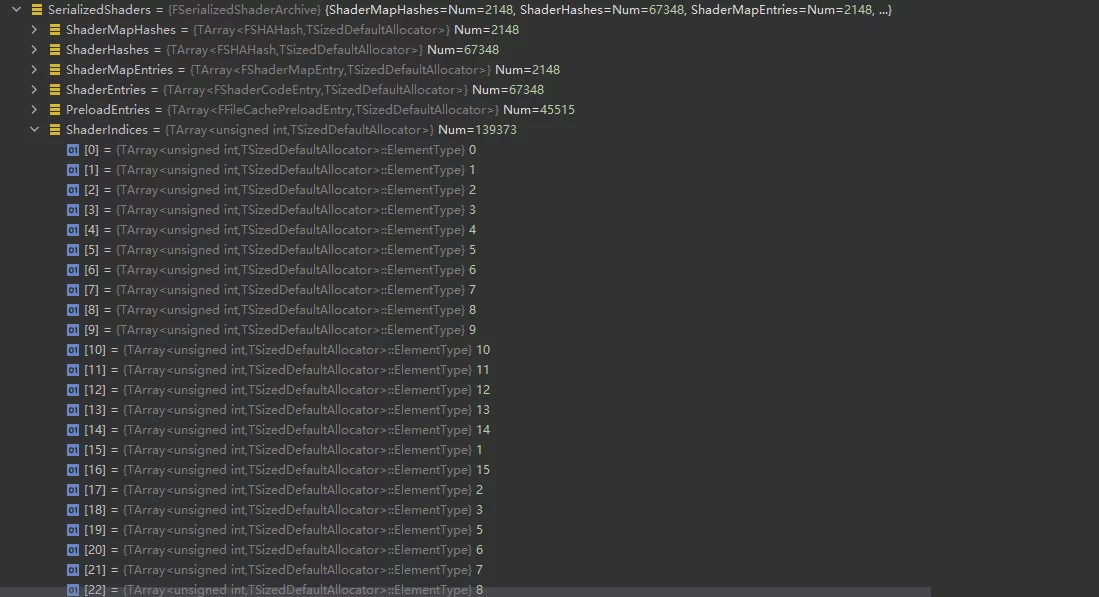
ShaderIndices, which only represent indices while the actual offsets of ShaderCode are stored inShaderEntries, known as Unique Shaders. - Upon serialization, a Material (with bShareCode enabled) will serialize the ShaderMap’s HASH into the uasset, facilitating runtime queries for the corresponding ShaderMap.
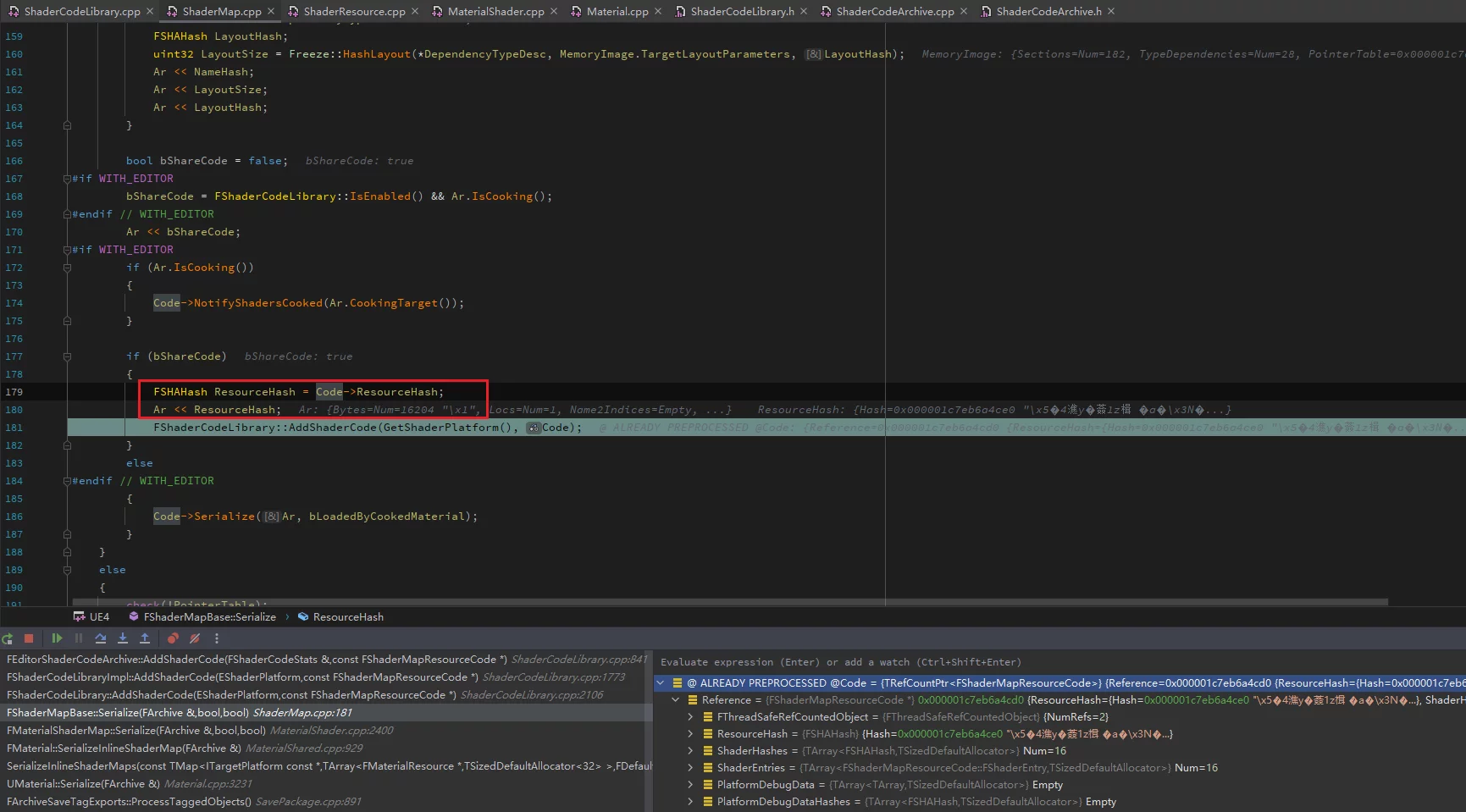
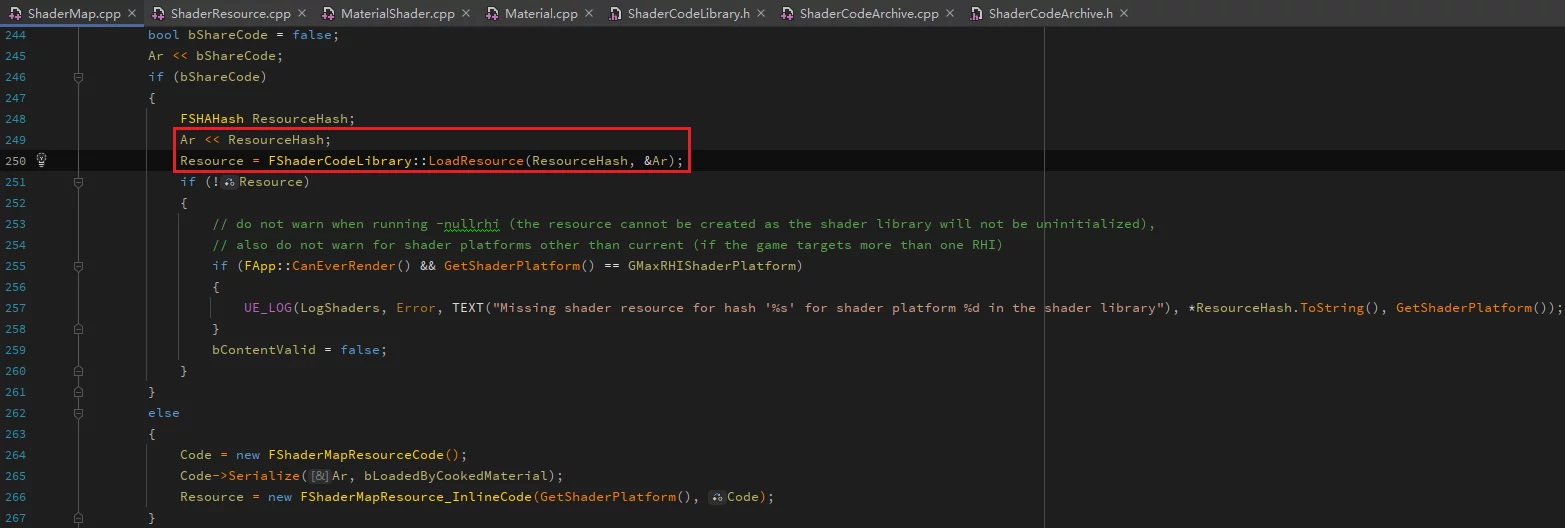
During reading, the FSHAHash value is utilized via FShaderCodeLibrary::LoadResource to load:
Reading ShaderCode
From the previous analysis, we recognize the storage structure of ShaderCode in ushaderbytecode.
FShaderCodeArchive possesses a function ReadShaderCode that can specify loading a particular ShaderCode: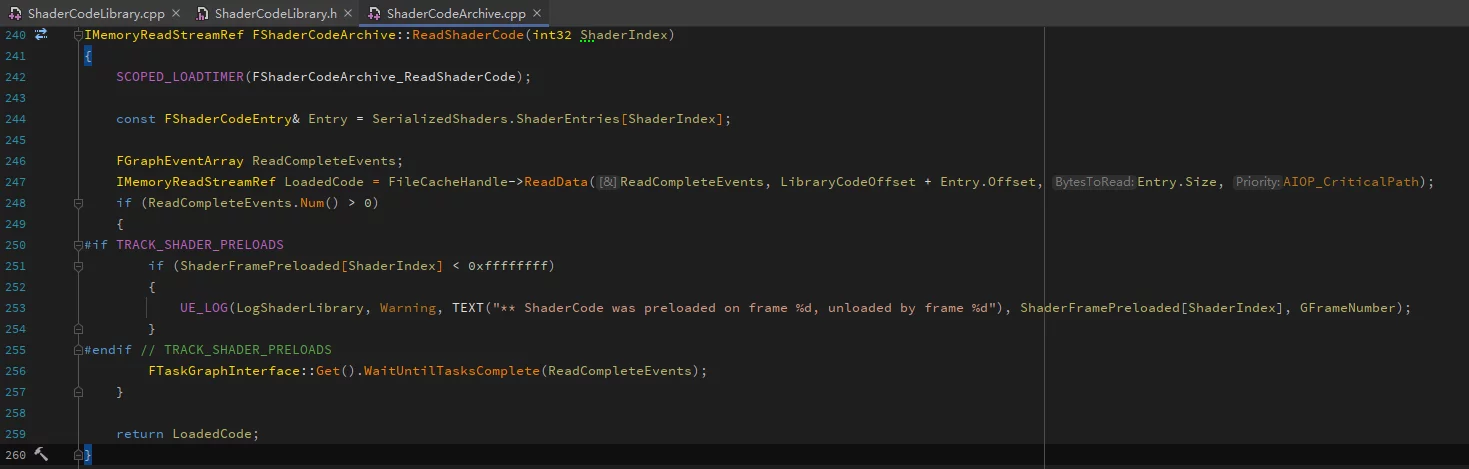
ShaderIndex can be obtained through ShaderHash using the following interface:
1 | int32 FSerializedShaderArchive::FindShader(const FSHAHash& Hash) const; |
The ShaderIndex corresponds to the index of the ShaderCode within ShaderEntries.
To traverse all Shaders within a ushaderbytecode:
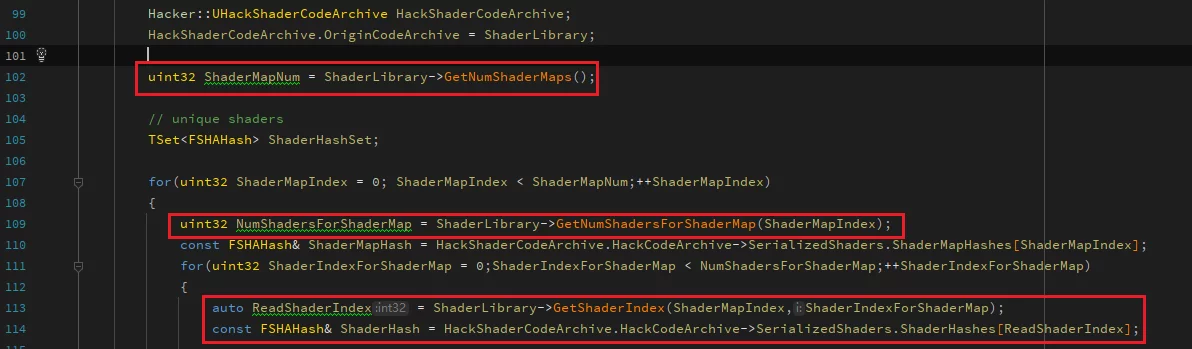
Once you have either the ShaderHash or ShaderIndex, you can directly use ReadShaderCode to retrieve the corresponding ShaderCode data:
1 | IMemoryReadStreamRef Code = Library->ReadShaderCode(ReadShaderIndex); |
However, this data is still compressed with LZ4 by default, and we need to decompress it via LZ4:
1 | FMemStackBase& MemStack = FMemStack::Get(); |
This way, we have directly read the original uncompressed ShaderCode from ushaderbytecode.
Whether storing them separately or training the dictionary using a MemoryBuffer is possible. Of course, the recommended practice is to copy the decompressed ShaderCode into a MemoryBuffer for later training dataset use, so that there is no need for IO, and the dictionary can be trained directly from memory.
Non-Engine Modification Implementation
The previous section introduced how to read ShaderCode from ushaderbytecode, but there is an issue: the FShaderCodeArchive class is not exported.
1 | class FShaderCodeArchive : public FRHIShaderLibrary{// ...} |
In external modules, access to its member functions is not possible, leading to linker errors.
Moreover, the ReadShaderCode function is a protected member, making it inaccessible from external symbols.
If the engine must be modified, the simplest change is to add RENDERCODE_API to export the symbol. Otherwise, you will need to use some clever techniques to achieve this, which can be referenced in my previous articles:
- Breaking C++ Class Access Control Mechanisms.
- Visibility and Accessibility of Access Control Mechanisms
The methods discussed in the articles can enable reading ShaderCode without modifying the engine, allowing it to be utilized even in the public engine. The specific methods will not be elaborated on in this article.
Training Dictionary in UE
In the previous article, the zstd command-line program was used for training:
1 | # Create Dictionary |
Based on the ShaderCode MemeryBuffer obtained in the last section, we can directly train the dictionary from memory.
Utilizing the ZSTD code in UE directly:
1 | ZDICTLIB_API size_t ZDICT_trainFromBuffer(void* dictBuffer, size_t dictBufferCapacity, |
We can encapsulate a helper function to create the dictionary:
1 | static buffer_t FUZ_createDictionary(const void* src, size_t srcSize, size_t blockSize, size_t requestedDictSize) |
This allows you to avoid saving ShaderCode to disk and then invoking ZSTD command-line training. The training logic is executed entirely in code based on in-memory data.
Dictionary Compression of shaderbytecode
Based on the contents of the previous two sections, we can directly train the ZSTD dictionary from ushaderbytecode.
So, what is the best practice for compressing the final ushaderbytecode using the ZSTD dictionary?
From the ushaderbytecode format analysis section, we know that the storage format of ushaderbytecode is as follows:
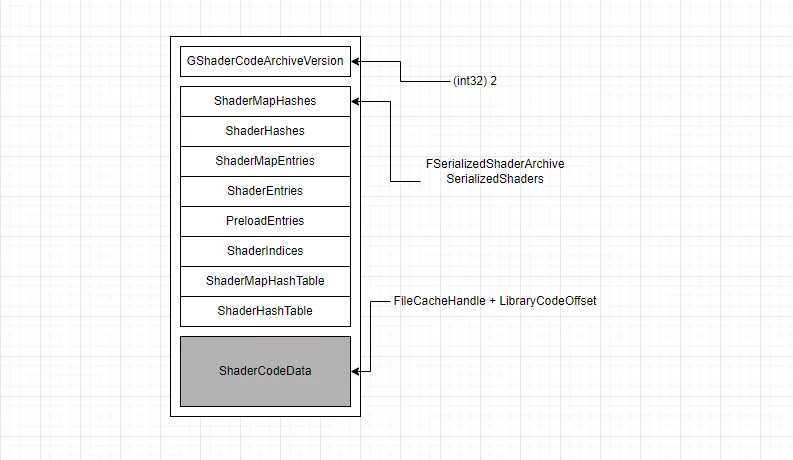
When loading a Shader, the ShaderHash is used to determine the index in ShaderIndices, which accesses ShaderEntries[index], and the content of ShaderEntries[index] provides the offset, size, and uncompressed size of the ShaderCode in the ShaderCodeData shown above, achieving deterministic reading of the ShaderCode.
If we want to generate another final ushaderbytecode based on the original ushaderbytecode through dictionary compression, we need to modify the following two parts:
- The ShaderCodeData after dictionary compression.
- Correct the offset and size (compressed size) of each Shader in
ShaderEntriesafter dictionary compression.
The specific implementation steps are:
- Read the original ushaderbytecode and save
SerializedShaders. - Sequentially read each ShaderCode and decompress using LZ4.
- Use ZSTD + dictionary to compress each ShaderCode, appending it to a global MemoryBuffer, allowing for obtaining the offset and size of the compressed ShaderCode in this MemoryBuffer.
- Update the new offset and size of each ShaderCode in the MemoryBuffer into the previously saved
SerializedShaders. - Finally, serialize
GShaderCodeArchiveVersion,SerializedShaders, andMemoryBufferto a file.
This way, you can directly create ushaderbytecode with dictionary compression from the default packaged ushaderbytecode, avoiding additional cooking processes.
ZSTD Optimization Strategies
Upgrade to the latest version of ZSTD (1.5.2), which has further improved compression rates compared to the previous integration (1.4.4).
On the interface level, it is optimized by using *usingCDict instead of *usingDict:
1 | // Recommended |
The *usingDict series of functions load the dictionary and are only recommended for single compressions. They can be very slow (by an order of magnitude) in scenarios requiring frequent compression using the same dictionary; therefore, *usingCDict should be used instead. The same also applies to decompression.
Dictionary Training and Compression Efficiency
Test Data:
- Shaderbytecode 256M
- Total original ShaderCode size (after LZ4 decompression): 682M
- 66579 Unique Shaders
Dictionary training:
Shader compression:
The majority of the ShaderCode’s compression time is around 1ms, fluctuating based on ShaderCode size.
The total time for dictionary training + generating final ushaderbytecode is less than 4 minutes, making the time consumption no longer a bottleneck.
Comparison of sizes between LZ4 compressed ushaderbytecode and ZSTD + dictionary compressed in actual projects:
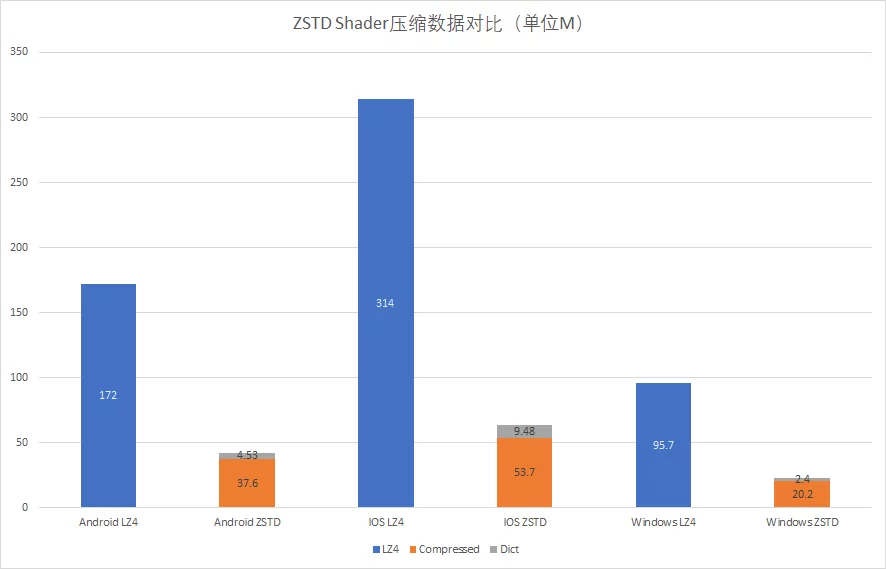
Runtime Example
I provide a runtime demo after packaging; the default package is through LZ4 compressed Shader, and I have provided one that contains the dictionary and the shaderbytecode compressed with the dictionary (including StarterContent and Global), which can be used to verify functionality and test runtime efficiency.
Download link: ZstdExample_WindowsNoEditor
Place ZstdShader_WindowsNoEditor_001_P.pak under Content/Paks to use the ZSTD and dictionary mode for reading the shader compressed with the dictionary from ShaderLibrary by default: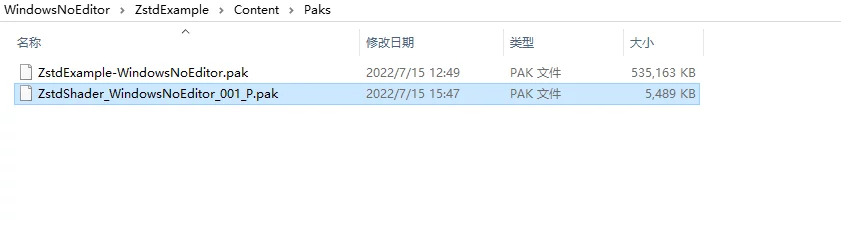
If you don’t put this Pak, the engine will use the default LZ4 compressed ushaderbytecode.
The runtime effect of using the ZSTD mode shows no Shader errors:
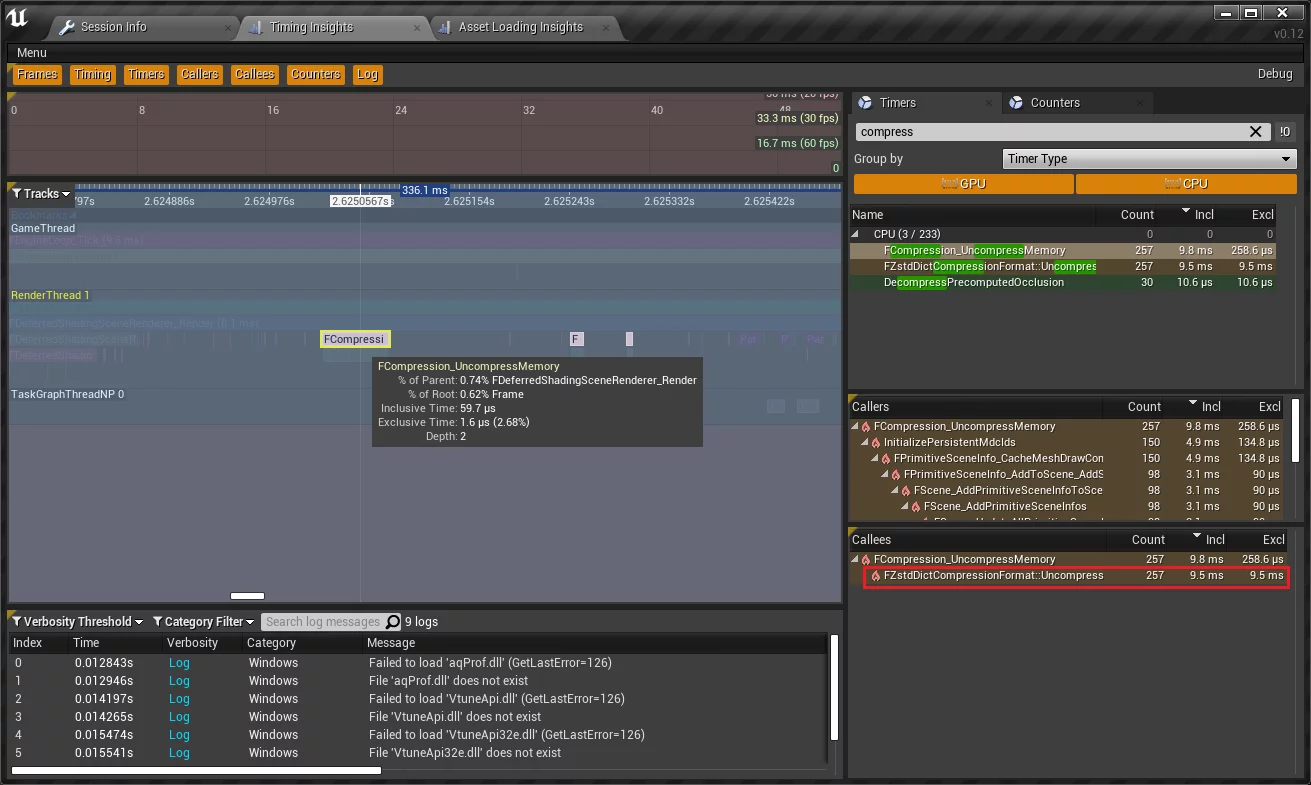
You can also analyze runtime performance using Unreal Insight:
1 | ZstdExample -windowed -resx=1280 -resy=720 -log -trace=cpu -tracehost=127.0.0.1 |
HotPatcher Integration
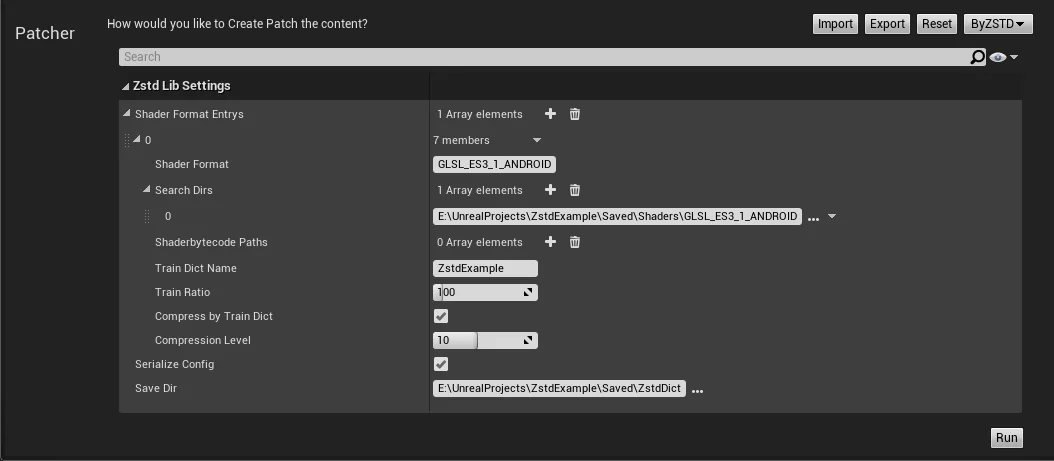
You can directly train the dictionary based on ushaderbytecode and use it to compress existing ushaderbytecode, minimizing operational costs.
Conclusion
This article shares an efficient ZSTD Shader dictionary training method, analyzing the file format of ushaderbytecode, and contrasting the methods for dumping ShaderCode, training the dictionary directly within UE. It also shares a method that does not require engine modifications, allowing seamless use in the public engine and reducing the management costs of engine changes.
The dictionary training and compression operations can be realized in a single call, significantly enhancing efficiency. This transforms dictionary training and compression into a completely Plugin-Only implementation, requiring no additional modifications and processes, clearing the obstacles for integration into HotPatcher, and it will later be released as an extension module of HotPatcher.

