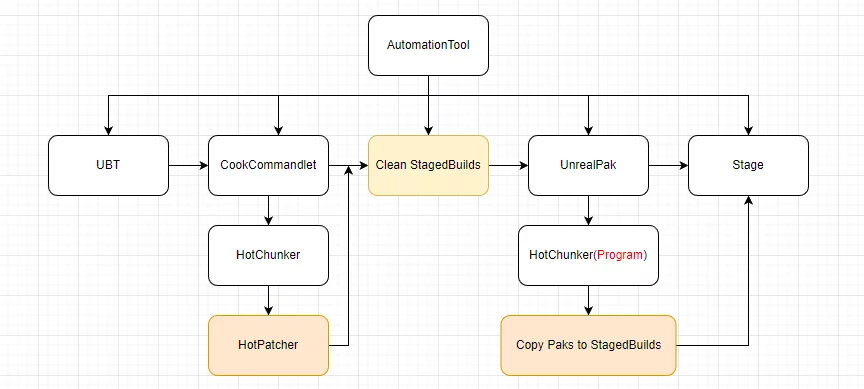
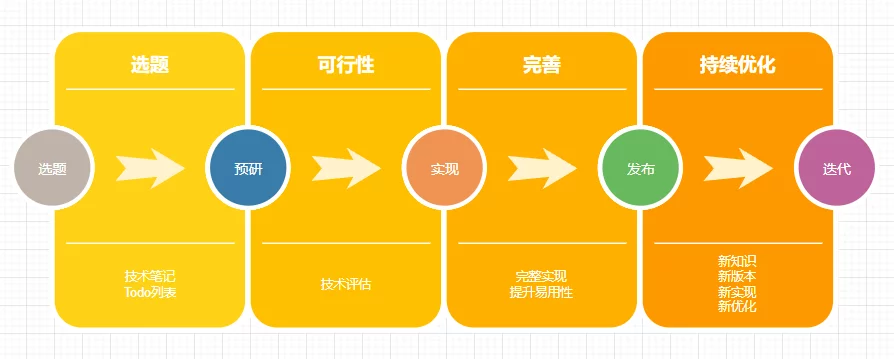
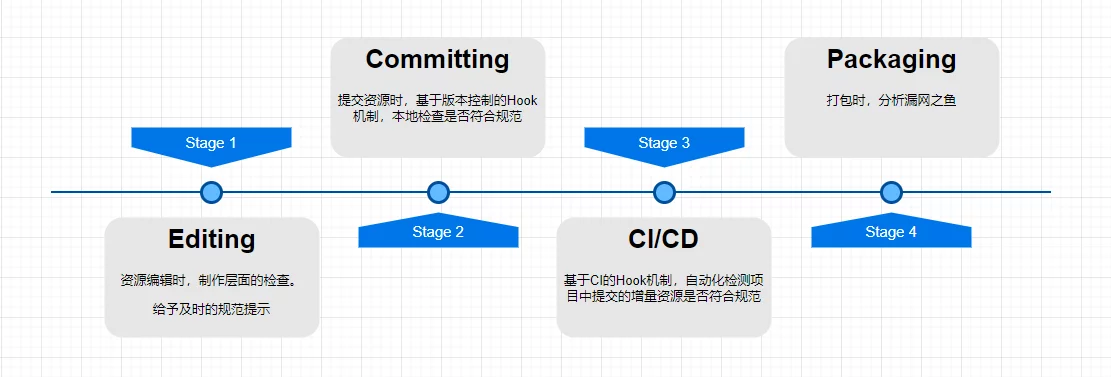
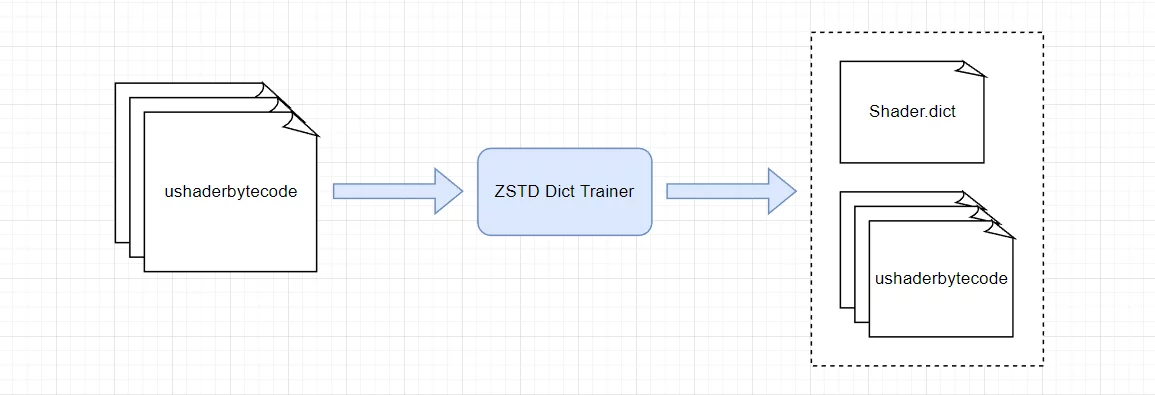
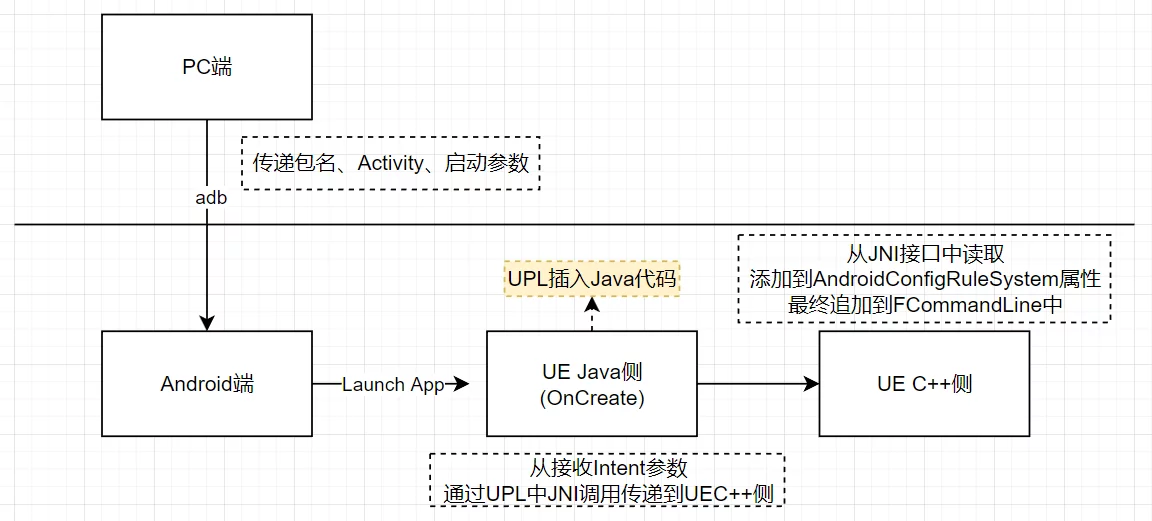
The Unreal Open Day 2022 was hosted by Epic in the form of an offline event combined with online live streaming. I am very happy to have attended the offline Unreal Open Day event this year. I recorded an online technical presentation and also participated in the live event in Shanghai. I am honored to have once again received the Outstanding Community Contributor award granted by Epic, which is both recognition and motivation for me. I look forward to the UE tech community continuing to grow and becoming the most vibrant game developer community. This article serves as a simple record, organizing the materials from UOD 2022, summarizing my participation in UOD, my presentation PPT, and related materials, as well as some photos taken at the UOD live event.